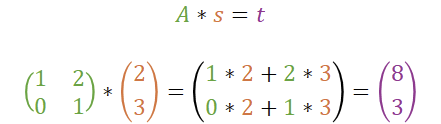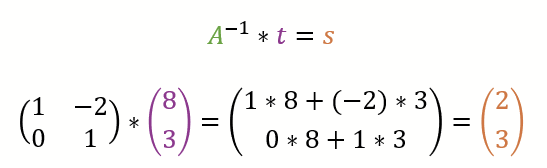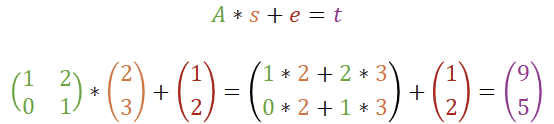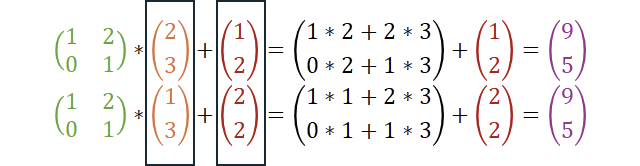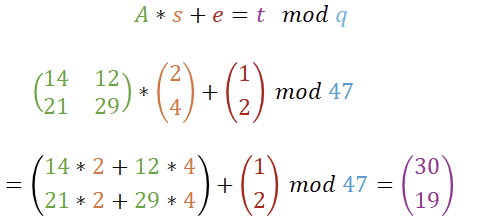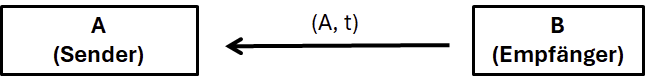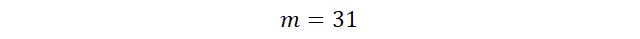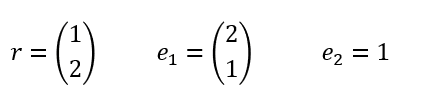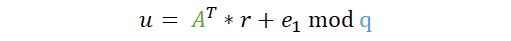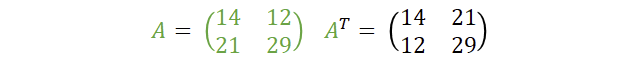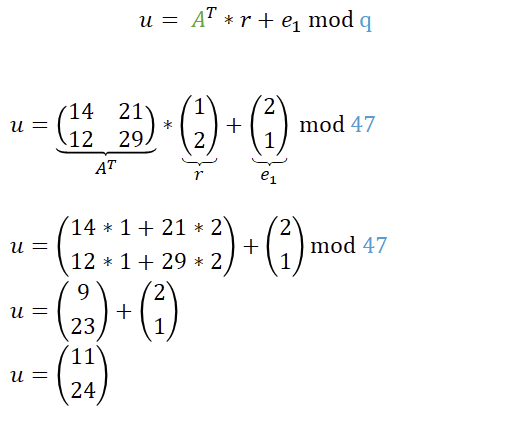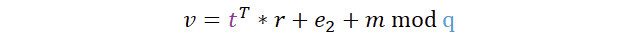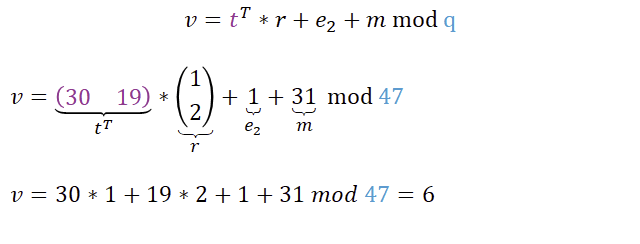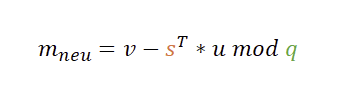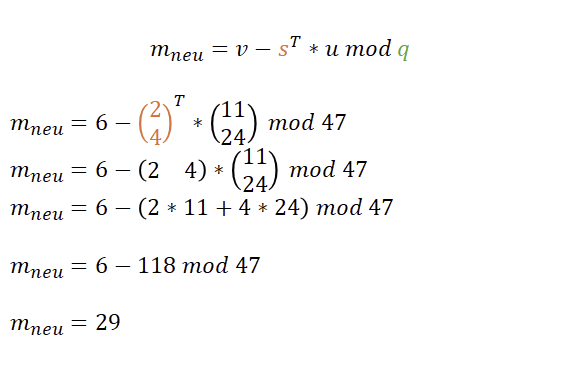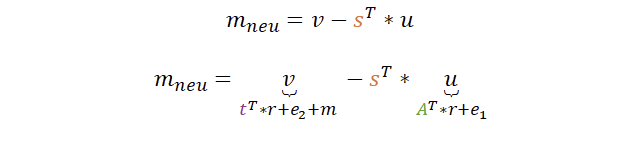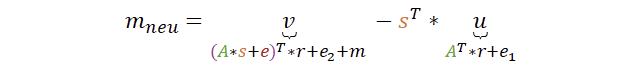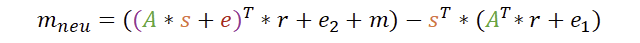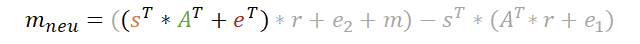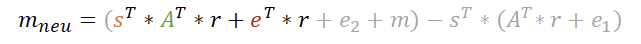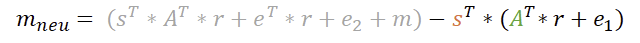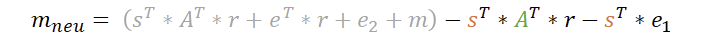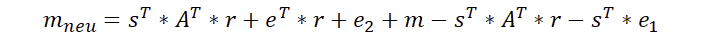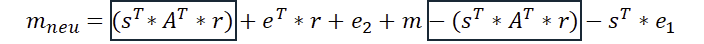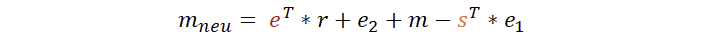In Foren oder auf Reddit gibt es immer wieder Diskussionen über die drohende Apokalypse im Netz, sollten Quantencomputer die etablierten asymmetrischen Verfahren brechen. Jedoch gibt es gute Gründe, optimistischer zu sein als noch vor drei Jahren. Cloudflare, als einer der größten Content-Delivery-Network-Anbieter, veröffentlicht regelmäßig Statistiken über das eigene Nutzerverhalten. Beispiele sind der Anteil von IPv4 (ca. 60 %) zu IPv6 (ca. 40 %) oder der am häufigsten verwendete User-Agent (Chrome).
Enthalten ist auch eine Statistik zur Nutzung quantencomputersicherer Schlüsselaustauschverfahren. Konkret ist in diesem Fall X25519MLKEM768 gemeint. Es handelt sich um eine Kombination aus einem auf elliptischen Kurven basierenden Schlüsselaustausch und Kyber (ML-KEM). Browserseitig wird dies u. a. von Mozilla Firefox und Google Chrome unterstützt.
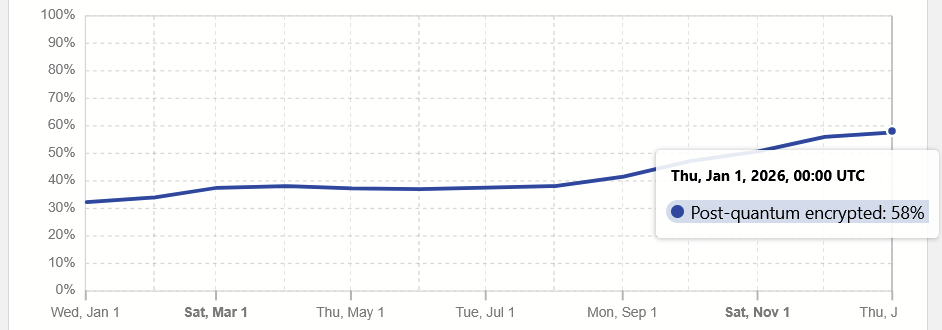
Während der Anteil im Januar 2024 bei 2,3 % lag, stieg er bis Januar 2025 auf ca. 30 %. Für Januar 2026 veröffentlicht Cloudflare einen Anteil von 58 %. Das bedeutet, dass bereits über die Hälfte des Traffics mit Verfahren abgesichert wird, die nach aktueller Einschätzung resistent gegenüber Quantencomputern sind.
Es ist zwar noch ein weiter Weg, insbesondere da in der Praxis ML-DSA-Zertifikate bislang kaum in Erscheinung treten. Dennoch ist es ein guter Anfang und eine insgesamt erfreuliche Entwicklung.
Im August 2025 wurde Ascon (AEAD 128) nach einem langen Auswahlprozess standardisiert. Es handelt sich dabei u. a. um eine Blockverschlüsselung, welche auch effizient auf ressourcenbeschränkten Geräten läuft, beispielsweise IoT-Sensoren, eingebettete Systemen oder für NFC.
Ähnlich wie beim SHA-3 wurde hier eine Sponge Konstrukation gewählt. Hierbei kann man sich die Verschlüsselung wie ein Schwamm vorstellen, in das IV, Nonce und Key „eingeschüttet“ wird. Beim Auspressen entsteht dann eine stark diffundierte Mischung, die mit dem Klartext verknüpft wird.
Obwohl Ascon eine blockweise Verarbeitung durchführt, arbeitet Ascon eher ähnlich einer Stromchiffre. Das „gemisch“ aus dem Schwamm wird einfach auf den Klartext aufgetragen; technischer ausgedrückt: es wird mit dem Klartext per XOR verknüpft. Aber anders als bei einer Stromchiffre wird der Klartext des aktuellen Blocks zur Generierung des nächsten Blocks verwendet. Dies bedeutet, der zu verschlüsselnde Klartext Block N hat eine Auswirkung auf den nachfolgenden Chiffretextblock N+1. Um bei der Metapher zu bleiben: der Klartext wird ebenfalls dem Schwamm zugeführt.
Dabei muss jedoch berücksichtigt werden, dass eine 1-Bit Änderung im Klartextblock nur zu einer 1-Bit Änderung des korrespondierenden Chiffretextblockes führt. Dieses Verhalten unterscheidet sich von klassischen Blockverschlüsselungen, sofern kein keystream-basierter Betriebsmodus zum Einsatz kommt. Im AES würde eine leichte Änderung des Klartextes zu umfassenden Änderungen des Chiffretextblockes führen. Die erwartete umfassende Änderung ergibt sich erst im nachfolgenden Block.
Das soll im Folgenden durch eine Tabelle veranschaulicht werden. Für beide Klartexte wurden die Einstellung gleich gewählt. Wie zu sehen ergibt sich durch die Änderung von D auf d eine Anpassung im ersten Nibble des Chiffretextes, sowie umfangreiche Änderungen im zweiten Block.
Hinweis: Der Schlüssel ist „test“ und die Nonce wurde auf 00000000000000000 0000000000000FF gesetzt.
Wie bei allen AEAD-Verfahren (Authenticated Encryption with Associated Data) entsteht am Ende der Verarbeitung ein Tag, welcher zur Authentisierung und zum Integritätsschutz dienen kann.
Um Ascon besser kennenzulernen oder das oben dargestellte Beispiel selbts ausprobieren zu können, steht jetzt eine Excel-Demo von Ascon unter den Projekten zur Verfügung.
Kürzlich bin ich im Internet über die Frage gestolpert, ob der Einsatz von PIM in VeraCrypt immer sinnvoll ist. Zum Beispiel auch dann, wenn man den Container mit einem 128-stelligen zufälligen Passwort abschließt. Dabei handelt es sich um die maximal unterstützte Passwortlänge der Applikation.
Kurz zur Erinnerung: Bei PIM (Personal Iterations Multiplier) wird das eingegebene Passwort über ein hardwareintensives Verfahren zu einem Schlüssel abgeleitet. Ein einfaches Beispiel hierfür ist eine vielfache Hashbildung: Anstelle eine Passphrase direkt zu verwenden, durchläuft diese vorher mehrmals eine Hashfunktion. Dieser Vorgang kann durch einen Angreifer nicht abgekürzt werden. Somit wäre dieser gezwungen, jeden möglichen Passwortkandidaten in gleicher Weise zu behandeln. Dies stellt einen hohen Aufwand dar und verhindert so einen Offline-Brute-Force-Angriff. Auf diese Weise sind sogar Passwörter aus einem Wörterbuch schwierig zu brechen.
Es ist wichtig zu verstehen, dass bei VeraCrypt das vom Benutzer eingegebene Passwort, mit oder ohne PIM, nicht unmittelbar verwendet wird, um die Inhaltsdaten auf der Festplatte zu verschlüsseln. Vielmehr wird vor der Formatierung ein durch Mausbewegungen erzeugter zufälliger Schlüssel verwendet. Dieser Schlüssel wird anschließend auf dem Datenträger abgelegt. Damit nicht jeder die Daten damit entschlüsseln kann, wird der Schlüssel durch die Passphrase des Benutzers verschlüsselt. An dieser Stelle kommt dann PIM zum Einsatz. Soll der Datenträger aufgeschlossen werden, wird die Passphrase des Benutzers verwendet, durchläuft aufgrund von PIM mehrere Iterationen und wird am Ende zu einem Schlüssel abgeleitet, welcher den Schlüssel für die Inhaltsdaten entschlüsselt.
Warum findet eine solche Entkoppelung zwischen Benutzerpassphrase und dem tatsächlichen Schlüssel statt? Ganz einfach: Auf diese Weise ist sichergestellt, dass der Schlüssel für die Inhaltsdaten wirklich zufällig ist und es ist möglich, das Benutzerpasswort zu ändern, ohne alle Daten mit der alten Passphrase entschlüsseln und mit der neuen Passphrase verschlüsseln zu müssen.
Die Inhaltsdaten sind also mit einem 256-Bit-Schlüssel gesichert, welcher durch die Mausbewegungen des Benutzers erzeugt wurde. Besser wird der Schutz also nicht. Somit sind nur Passphrasen sinnvoll, die diese 256 Bit abdecken. Jedes zusätzliche Zeichen führt nur zu einer Dopplung, sodass zwei unterschiedliche Passwörter denselben Schlüssel erzeugen. Unter der Prämisse, dass wir Groß- und Kleinbuchstaben und die Ziffern 0 bis 9 verwenden, hilft der Logarithmus zur Bestimmung der maximal sinnvollen Länge:
Mehr als 43 Stellen sind für ein Passwort also nicht sinnvoll, sofern die Zeichen zufällig gewählt wurden. Mit 43 zufälligen Zeichen aus diesem Alphabet bekommen wir einen perfekten 256-Bit-Schlüssel.
Auf diese Weise lässt sich die ursprüngliche Frage beantworten. Wenn ein Angriff ohnehin auf die vollständige Schlüsselsuche aller 256-Bit-Schlüssel hinauslaufen müsste, könnte der durch PIM gesicherte Teil übersprungen werden. Mit einem zufällig gewählten Schlüssel, welcher die volle Schlüssellänge der Blockchiffre abdeckt, bringt der Einsatz von PIM somit keinen zusätzlichen Nutzen.
Kürzlich kam in einer Kommentarspalte zu einem Video die Frage auf, ob die Anforderung zur Bereitstellung von SSL/TLS gesetzlich normiert ist. Viele denken, dass die Bereitstellung eher optional ist, sofern keine personenbezogenen Daten übertragen werden. Aber dennoch bleibt die Frage, wie es abseits des Datenschutzes mit einer solchen Anforderung aussieht. Immerhin existieren noch Webseiten, die kein HTTPS anbieten, auch wenn es immer weniger werden.
Tatsächlich gab es aber schon im alten Telemediengesetz eine Regelung dazu und zwar im § 13 Abs. 7 TMG:
Diensteanbieter haben, soweit dies technisch möglich und wirtschaftlich zumutbar ist, im Rahmen ihrer jeweiligen Verantwortlichkeit für geschäftsmäßig angebotene Telemedien durch technische und organisatorische Vorkehrungen sicherzustellen, dass
kein unerlaubter Zugriff auf die für ihre Telemedienangebote genutzten technischen Einrichtungen möglich ist und
diese a) gegen Verletzungen des Schutzes personenbezogener Daten und b) gegen Störungen, auch soweit sie durch äußere Angriffe bedingt sind, gesichert sind.
Vorkehrungen nach Satz 1 müssen den Stand der Technik berücksichtigen. Eine Maßnahme nach Satz 1 ist insbesondere die Anwendung eines als sicher anerkannten Verschlüsselungsverfahrens.
Wer sich die Frage stellt, wer hier als „Diensteanbieter“ gilt, dann lässt sie sich dahingehend beantworten, dass es die selben natürlichen oder juristischen Personen sind, die ein Impressum anbieten müssen. Ich lehne mich so weit aus dem Fenster, dass dies für die deutliche Mehrheit der deutschsprachigen Webseiten der Fall ist.
Nun ist das TMG nicht mehr in Kraft und es könnte sich die Frage stellen, inwieweit eine solche Regelung in die neuen Normen übernommen wurde (oder nicht). Im Digitale Dienste Gesetz war dahingehend nichts auffindbar. Fündig wird man allerdings im § 19 Abs. 4 TDDDG (Telekommunikation-Digitale-Dienste-Datenschutz-Gesetz):
Anbieter von digitalen Diensten haben, soweit dies technisch möglich und wirtschaftlich zumutbar ist, im Rahmen ihrer jeweiligen Verantwortlichkeit für geschäftsmäßig angebotene digitale Dienste durch technische und organisatorische Vorkehrungen sicherzustellen, dass
kein unerlaubter Zugriff auf die technischen Einrichtungen, die sie für das Angebot ihrer digitalen Dienste nutzen, möglich ist und
die technischen Einrichtungen nach Nummer 1 gesichert sind gegen Störungen, auch gegen solche, die durch äußere Angriffe bedingt sind.
Vorkehrungen nach Satz 1 müssen den Stand der Technik berücksichtigen. Eine Vorkehrung nach Satz 1 ist insbesondere die Anwendung eines als sicher anerkannten Verschlüsselungsverfahrens. Anordnungen des Bundesamtes für Sicherheit in der Informationstechnik nach § 7d Satz 1 BSI-Gesetz bleiben unberührt.
Alte und neue Anforderung wirken also recht ähnlich. Meiner Einschätzung nach lässt sich somit, vorher wie nachher, die Pflicht auf TLS aus dem TDDDG ableiten. Allerdings würde es einem voraussichtlich ohnehin nicht gelingen, aus den Anforderungen des Art. 32 DSGVO herauszukommen.
Als ich 2008 diesen Blog eröffnete, diente er primär dazu, kuriose Funde im Netz zu kommentieren – beispielsweise eine schlecht implementierte Verschlüsselung oder falsche Darstellungen in Artikeln.
Zunächst gibt es ein paar Kleinigkeiten die mich stören, weil sie einfach unscharf sind. Ein Beispiel hierfür ist der folgende Absatz:
Wie das NIST festgestellt hat, basieren herkömmliche kryptografische Algorithmen auf der „Schwierigkeit, die herkömmliche Computer beim Faktorisieren großer Zahlen haben“.
Das ist einfach deshalb unscharf, weil vor allem das RSA- und das Rabin-Verfahren darauf beruhen. ElGamal sowie die Schlüsselaustauschverfahren wie Diffie-Hellman oder ECC-Verfahren haben nichts mit der Primfaktorzerlegung zu tun, denn diese basieren auf dem Problem des diskreten Logarithmus. Außerdem werden in dieser Formulierung die symmetrische Verfahren nicht deutlich genug ausgeschlossen. Richtig ist jedoch, dass der Shor-Algorithmus eine Bedrohung für die gängigen asymmetrischen Verfahren darstellt.
Auch wusste der Autor offensichtlich nicht wofür KEM steht. Denn im folgenden Absatz steckt der Irrtum, Kyber sei ein Verschlüsselungsverfahren:
Die ersten fertiggestellten Standards des PQC-Standardisierungsprojekts des NIST sind ML-KEM (basierend auf dem CRYSTALS-Kyber-Algorithmus), der als primärer Standard für die allgemeine Verschlüsselung dient; […]
Das KEM in ML-KEM steht für Key Encapsulation Mechanism. Das bedeutet, dass auf der einen Seite ein Schlüssel eingepackt und auf der anderen Seite ausgepackt wird. Im Vordergrund steht dabei der Schlüsselaustausch, denn mit Kyber lassen sich nur 256-Bit „einpacken“. Eben genau so viel, wie man für einen sicheren Schlüsselaustausch benötigt. Es wird also keinesfalls ein Verfahren für die allgemeine Verschlüsselung angeboten.
Das sind aber Kleinigkeiten, über die man grundsätzlich hinwegsehen kann. Gegen Ende wird der Artikel jedoch extrem konfus.
Was bedeutet das für die Passwörter, mit denen wir uns online anmelden?
Nichts. Gar nichts. Denn die Standardisierung von quantencomputerresistenten asymmetrischen Verfahren hat nichts mit Passwörtern zu tun. Passwörter werden entweder über ein Schlüsselableitungsverfahren (KDF) für eine symmetrische Chiffre verwendet, oder zur Authentifizierung in Form eines vorher ausgetauschten Geheimnisses (Pre-shared Key). Beides hat nichts mit Quantencomputern zu tun und hierfür hätten wir die neuen Verfahren auch nicht benötigt.
Sowohl Unternehmen als auch Organisationen werden weiterhin auf die Vorteile der Passwortsicherheit setzen, insbesondere auf ihre Einfachheit, Flexibilität (sie lassen sich leicht zurücksetzen) und grundlegende Effektivität (sie sind entweder richtig oder falsch).
Was dieser Absatz aussagen soll? Leider weiß ich es nicht.
Es geht vielmehr darum, stärkere Schlösser zu bauen, um unsere wichtigen Daten und Ressourcen zu schützen, anstatt sie komplett zu entfernen.
Wir haben bereits starke symmetrische Verfahren, um Daten zu schützen, deren Sicherheit sich durch Kaskadierung noch weiter steigern lässt. Die stärksten Schlösser hierfür stehen uns schon seit Langem zur Verfügung – die Standardisierung bringt in diesem Bereich nichts Neues.
Der Artikel fordert zur Prüfung auf, „ob Ihre aktuelle Passwortsicherheit Quantenangriffen standhalten kann“. Mir ist unklar, was ich jetzt tun soll.
Der Vollständigkeit halber sei angemerkt, dass der sogenannte Grover-Algorithmus eine Gefahr für symmetrische Verschlüsselung und Hashverfahren darstellen kann. Hier ist die Skalierung zu längeren Block- und Schlüssellängen jedoch so einfach, dass dieser Umstand überwiegend vernachlässigt werden kann.
Ich freue mich, wenn es Nachrichten aus der Welt der Kryptologie gibt. Etwas traurig finde ich, wenn sie so missverständlich, fehlerhaft oder gar irreführend sind. Es ist zu erwarten, dass es an den fehlenden Kenntnissen des Autors lag. Das ist nicht schlimm, niemand kann alles wissen. In diesem Fall sollte man sich aber nur so weit aus den Fenster lehnen, wie es die Sicherheit erlaubt.
Das BSI hat seine technische Richtlinie zu Schlüssellängen aktualisiert (Dokument vom Stand 31.01.2025). Wie erwartet ist ML-KEM (Kyber) auch mit zwei Schlüssellängen in die Richtlinie aufgenommen worden. Es wäre interessant zu wissen, weshalb die kleinste Variante hier nicht erwähnt wird.
Noch interessanter ist jedoch, dass der AES-GCM-SIV als Chiffre bzw. Betriebsmodus-Empfehlung aufgenommen wurde. Um SIV besser verstehen zu können, ist es vielleicht sinnvoll zuerst ein paar Schritte zurück zu gehen.
AES, grundsätzlich eine Blockchiffre, arbeitet allerdings durch ein CCM oder GCM Betriebsmodus äquivalent zu einer Stromchiffre. Das bedeutet, dass die Funktion genutzt wird um einen Schlüsselstrom zu erzeugen, der bitweise auf den Klartext appliziert wird (xor).
Der gleiche Schlüssel erzeugt hierbei den gleichen Schlüsselstrom. Damit sich der Schlüsselstrom bei gleichem Schlüssel ändert, wird eine sogenannte Nonce als Initialisierungsvektor verwendet. Eine Nonce ist Zahl, die dem Namen nach nur einmal verwendet werden darf. Wird dieselbe Nonce mehrfach verwendet, wird auch der gleiche Schlüsselstrom erzeugt. Ein solcher Fehler macht AES-GCM leicht angreifbar.
Somit wäre die doppelte Verwendung einer Nonce eine Katastrophe. In Umgebungen, in denen eine solche doppelte Verwendung nicht ganz ausgeschlossen werden kann, kann nun AES-GCM-SIV zum Einsatz kommen.
Die Idee hinter SIV ist, dass diese zur Verschlüsselung verwendete Initialisierungsvektor zusätzlich zu weiteren Daten auch vom Klartext abhängig ist. Somit wird die Gefahr der doppelten Verwendung reduziert. Wird zufälligerweise die gleiche Nonce verwendet, müsste auch der Klartext gleich sein, damit derselbe IV und somit derselbe Schlüsselstrom erzeugt wird. Das Ganze natürlich nicht mit absoluter, aber nunmal mit praktischer Sicherheit.
Es handelt sich deshalb um einen generierten „synthetischen“ Initialisierungsvektor, was AES-GCM-SIV seinen Namen gibt.
Als in den 2000er-Jahren der AES ausgewählt wurde, gab es zunächst mehrere Varianten mit verschiedenen Blocklängen. So unterstützte der Rijndael-Algorithmus auch Blocklängen von 192- und 256-Bit. Später im Prozess entschied man auf die größeren Blocklängen zu verzichten und setzte diese konstant auf 128-Bit. Dies hatte auch den Vorteil, dass der AES zur Verwendung nicht übermäßig parametrisiert werden muss: mit AES-128, AES-192 und AES-256 ist das Verfahren stets hinreichend beschrieben: Die Zahl steht dabei nur für die Schlüssellänge, die Blocklänge ist immer 128-Bit.
Nun, 25 Jahre später, denkt das NIST laut über eine Variante mit einer größeren Blocklänge nach. Genauer gesagt eine 256-Bit Variante. Dabei wäre die Schlüssellänge fest auf 256 gesetzt. Bis Juni 2025 sind Interessierte aus aller Welt dazu eingeladen, ihre Meinung zu äußern.
Eine solche Erweiterung ist aus mehreren Gründen ganz interessant. Denn die Autoren haben bereits in der ursprünglichen Dokumentation angedeutet, dass sich mit einer größeren Blocklänge auch weitere Einsatzzwecke ergeben könnten:
The block lengths of 192 and 256 bits allow the construction of a collision-resistant iterated hash function using Rijndael as the compression function. The block length of 128 bits is not considered sufficient for this purpose nowadays.
Es ist jedoch recht fraglich, ob der AES hierfür heute noch einen Einsatz finden würde.
Viel wahrscheinlicher ist dieser Vorstoß der Tatsache geschuldet, dass der AES heute überwiegend in Kombination mit einem Betriebsmodus zum Einsatz kommt, welcher die Blockchiffre in eine Stromchiffre wandelt. Alle Betriebsmodi in TLS 1.3 sind Counter-Varianten: GCM und CCM. Selbst mit ein paar AES Runden mehr entsteht hier auf ein Schlag der doppelte Schlüsselstrom. Das dürfte ein recht überzeugendes Argument dafür darstellen.
Um Kyber leichter erklären zu können, habe ich die notwendigen Matrizen-Operationen im Polynomring über Lambda-Funktionen in Excel implementiert. In einem aktuellen Microsoft Excel sollten diese funktionieren. In dieser Variante ist somit die Verschlüsselung (genauer: Schlüsselaustausch) von bis zu vier Bits möglich.
Für die Nutzung beider Beispiele wird voraussichtlich ein Microsoft Excel 365 oder 2024 erforderlich sein, in denen Lambda-Funktionen unterstützt werden.
Kyberkristalle geben dem Lichtschwert seine Farbe – das sollte allgemein bekannt sein. Darüber hinaus handelt es sich bei CRYSTALS-Kyber um ein vom NIST empfohlenes asymmetrischen Verfahren, das auch im Zeitalter der Quantencomputer noch sicher ist. An dieser Stelle ist einzuräumen, dass wir mit der Aussage noch vorsichtig sein müssen. Jüngst wurden Seitenkanalangriffe bekannt und zur Berechnung der Sicherheit gab es einen wirklich dummen Rechenfehler. Im April 2024 stellte sich kurzzeitig Panik ein: in einem Papier wurde Kyber als gebrochen erklärt. Allerdings wurde die Aussage von den Autoren recht zügig widerrufen.
WolfSSL hat mittlerweile Kyber integriert. Auch Amazon Web Services scheint Kyber mittlerweile zu verwenden. Es ist meine feste Erwartung, dass Kyber auch in TLS 1.4 Einzug halten wird. Im Signal-Protokoll ist es schon produktiv im Einsatz. Im Februar 2024 wurde von Apple verkündet, dass Kyber für IMessage eingesetzt werden soll.
Ich habe mir deshalb die Arbeit gemacht, Kyber genauer zu betrachten und so aufzubereiten, dass es ohne tiefgehende mathematischen Kenntnisse nachvollziehbar wird. Achso, falls die Frage aufkam: Ja, die Anspielung an Star Wars war bei der Namenswahl von den Entwicklern beabsichtigt.
Hinweis: Im Folgenden wird eine vereinfachte Form von Kyber erläutert, um das Konzept und die Falltür leichter verständlich zu machen. Eine noch detailliertere und orginalgetreuere Darstellung findet sich in diesem Blogartikel einschließlich Excel-Demo.
Die Falltür
Der erste Schritt, um eine asymmetrische Verschlüsselung zu verstehen, ist die Betrachtung der Falltürfunktion. Das ist die Funktion, die sich in eine Richtung leicht berechnen lässt, jedoch nur schwer umzukehren ist. Genauer soll die Umkehrung, also die Entschlüsselung, nur mit dem Wissen des privaten Schlüssels möglich sein. Bei Kyber besteht die Falltür aus einem Problem, welches eigentlich leicht zu verstehen ist, jedoch auch für Quantencomputer ein schwieriges Problem darstellen soll: Learning with Errors (LWE).
Wir können uns LWE mal ganz langsam über simple Grundlagen aus der linearen Algebra nähern. Das Produkt einer Matrix A mit einem Vektor s ergibt einen Vektor t; hier mit entsprechendem Berechnungsbeispiel.
Nicht ganz neu ist, dass wir (je nach Matrix A) die Operation umkehren können. Mit dem Gauß-Verfahren gelingt dies mit polynomieller Laufzeitkomplexität. Mit A-1 wird hier die Umkehrung durchgeführt, also das s aus A und t berechnet.
Wir erweitern nun die ursprüngliche Berechnung um eine weitere additive Komponente: den Fehler e. Nach der Multiplikation von Matrix und Vektor addieren wir diesen Fehler hinzu.
Die Umkehrung hierfür ist jedoch ein schwieriges Problem. Es ist die Schwierigkeit, aus der Gleichung (A und t) mit unbekanntem Fehler e die ursprüngliche Variable s zu bestimmen. Ein Teil des Problems ist, dass es bei unbekanntem s und e mehrere Möglichkeiten gibt, die Gleichung zu erfüllen. Es gibt also nicht länger eine eindeutige Lösung, sondern es kommen verschiedene (s,e)-Kombinationen in Frage.
Wir sind aber noch nicht ganz fertig, denn für LWE kommt noch ein weiteres „Problem“ hinzu. Wir würden es auch vermissen, wenn es fehlen würde: eine Primzahl. Somit werden die Komponenten der Matrizen und Vektoren (und die Berechnungsergenisse) modulo q gerechnet.
Bei diesen kleinen Zahlen scheint das mit dem Modulo eher unsinnig. Daher werden wir A und q für die weiteren Beispiele etwas vergrößern. Wir setzen daher q auf 47 und nehmen auch für A und s neue Werte. Kyber schreibt vor, dass e und s keine großen Werte aufweisen sollen und wir werden später auch leicht nachvollziehen können, weshalb das so ist. Bitte einen kurzen Moment Zeit nehmen, um die Berechnung nachzuvollziehen, die neuen Werte werden auch bis zum Ende beibehalten.
Tatsächlich ist damit die Falltür für Kyber schon vollständig erläutert. Die Matrix A und das Ergebnis t stellen den öffentlichen Schlüssel dar. Der Vektor s ist der private Schlüssel. Bei e handelt es sich um einen Fehler der normalverteilt gewürfelt wird. Für s und e besteht bei Kyber die Einschränkung, dass die Werte nicht zu hoch sein dürfen. Die Primzahl q ist Teil des Verfahrens und ändert sich nicht: im „echten“ Kyber ist q immer 3329.
Merke: (A, t) ist der öffentliche Schlüssel, bei s handelt es sich um den geheimen Schlüssel und e ist ein Fehlervektor.
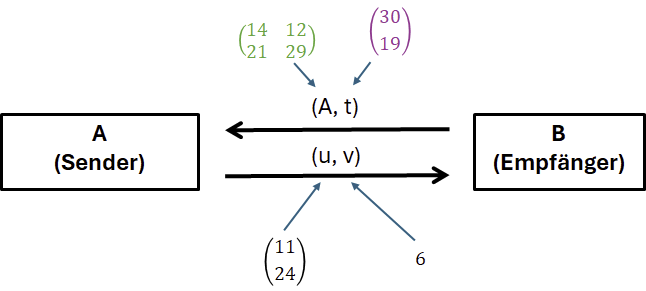
Jetzt, wo das Schlüsselmaterial generiert ist, kann dies übermittelt werden. In unserem Fall ist der Sender die Person, die gerne eine Nachricht übermitteln möchte, und der Empfänger soll diese im Anschluss entschlüsseln. Somit hat der Empfänger das Schlüsselmaterial generiert und übermittelt dies dem Sender.
Bevor es weitergeht, folgt an dieser Stelle noch ein kleiner Disclaimer. Die hier vorgestellte Falltür basiert auf dem Learning with Errors (LWE) Problem. Bei Kyber kommt allerdings Module Learning with Errors M-LWE zum Einsatz. Das ändert nichts daran, dass es sich bei A um eine Matrix und bei s, e und t um Vektoren handelt. Allerdings sind die Komponenten der Matrizen und Vektoren keine Elemente aus einem Restklassenring, sondern es sind Polynome aus einem Polynomring. Dies bedeutet, dass Addition (trivial) und Multiplikation (etwas schwieriger aufgrund Polynomdivision) in dieser algebraischen Struktur durchgeführt wird. Das ist für die Verschlüsselung leider nicht ganz unwichtig, wenn mehr als nur ein Bit verschlüsselt werden soll. Aber an dieser Stelle wollte ich von diesem Polynomring zunächst abstrahieren. Aufgrund der Abstraktion können wir deshalb nur ein Bit verschlüsseln, was uns aber erstmal genügen muss. Wem das doch nicht genügt, bekommt in diesem Blogartikel Kyber auf Basis von M-LWE näher erläutert.
Der Einsatz eines Polynomrings ändert im Übrigen nichts daran, dass alle Koeffizienten Modulo q gerechnet werden. Primzahlen sind und bleiben wichtig: auch für Verschlüsselungen im Zeitalter der Quantencomputer.
Verschlüsselung
Wir haben nun erfolgreich Schlüsselmaterial erzeugt. Der Sender, der eine Nachricht verschlüsseln möchte, wird nun im Folgenden zwei Komponenten erzeugen: u und v. Wir wissen noch nicht, wie diese aussehen. Aber vermutlich lässt sich schon erahnen, dass eine dieser Komponenten die Nachricht m enthalten wird. Spoileralarm: In v ist die verschlüsselte Nachricht enthalten und u wird benötigt um diese, mit Kenntnis des privaten Schlüssels s, beim Empfänger auszupacken. Wir können also v als ein gut verpacktes DHL-Paket mit unserer Nachricht ansehen und mit u und s können wir den Karton öffnen.
Bevor wir uns mit u und v befassen, müssen wir zunächst über die Nachricht m sprechen. Eine Nachricht besteht üblicherweise aus mehreren Bits. Mit der hier betrachteten Vereinfachung (ohne Polynomring) können wir leider nur genau ein Bit verschlüsseln. Das ist natürlich weder sinnvoll noch sicher, aber einfacher zu verstehen. Manchmal genügt auch ein einfaches Ja oder Nein, oder?
Um in Kyber eine Nachricht zu übermitteln, muss diese vorher skaliert werden. Wir haben uns bereits oben auf ein q=47 geeinigt. Angenommen, wir möchten ein „Ja“ verschlüsseln, dann wählen wir für m eine Zahl oberhalb der 24 (das ist q/2 aufgerundet). Wir kodieren eine 1, also ein „Ja“, z. B. mit m=31. Hätten wir hingegen eine 0, also ein „Nein“, wäre z. B. m=11 möglich gewesen. Große Zahl ist 1, kleine Zahl ist 0 und es ist erstmal egal, ob 30, 31 oder 32 für das Ja steht. Das passiert auch in Kyber mit jedem Bit der Nachricht. Warum wir das machen, wird später erläutert. Unser „Ja“ wurde also mit m=31 kodiert – wenn wir von der Nachricht sprechen, ist also die 31 gemeint und steht für ein Ja.
Zur weiteren Verschlüsselung werden ein Vektor r, ein Vektor e1 und ein Skalar e2 mit zufälligen Werten benötigt, allerdings: Wie oben bei e und s sollen es kleine Koeffizienten sein, also in diesem Beispiel mit 1, 2 oder 3. An dieser Stelle nochmal ganz deutlich: Das sind zufällig gewählte Werte, wir können diese auch unbeschadet anders wählen!
Mir ist bewusst, dass das jetzt ein ganzer Haufen Buchstaben sind. A, s, e, t, u, v, r… damit könnte man in Scrabble schon viele Punkte erzielen! Es ist ohne Frage schwierig, hier den Überblick zu behalten. Die gute Nachricht ist: r, e1 und e2 können wir unmittelbar nach der Verschlüsselung wieder vergessen. Diese Werte brauchen wir dann nicht mehr und haben somit nur einen kurzen Auftritt.
Nun sind wir bereit, um uns u und v genauer anzusehen. Das schmerzt möglicherweise auf den ersten Blick, wird dann aber mit dem zweiten Blick besser. Beginnen wir mit u.
Das „T“ im Exponenten beschreibt hier die transponierte Matrix. Transponieren bedeutet, dass wir die Matrix einmal an der Hauptdiagonalen spiegeln: Aus Zeilen werden Spalten und umgekehrt. Schauen wir uns das an:
Zugegeben, bei einer 2×2-Matrix ist transponieren nicht so aufregend: Die Hauptdiagonale bleibt unverändert und es tauschen nur zwei Komponenten. Ist halt so!
Um u zu berechnen, müssen wir also die bereits bekannte Matrix A transponieren und mit dem Zufallsvektor r multiplizieren und e1 addieren. Falls es nicht direkt bemerkt wurde: bei u kommt wieder unsere Falltür ins Spiel, nur mit neuen Werten. Die Falltür wurde also sowohl zur Generierung des öffentlichen Schlüssels benutzt als auch hier zur Verschlüsselung. Warum das A transponiert wurde, wird später noch erläutert.
Wenn man es ganz genau betrachtet, wurde hier das gewürfelte r durch das transponierte A und mit e1 „verschlüsselt“. Somit ist das r bei Übermittlung nicht mehr sichtbar und ohne Lösung des LWE-Problems auch nicht (einfach) berechenbar.
Jetzt schauen wir uns die zweite Komponente, also das v näher an:
Hierfür wird die t-Komponente aus dem öffentlichen Schlüssel transponiert, mit dem Zufallsfektor r multipliziert und sowohl der Fehler e2 als auch die Nachricht m aufaddiert. Am Ende, wie immer, modulo q.
Die Struktur ist recht ähnlich wie zuvor, jedoch handelte es sich bei A um eine Matrix und bei t um einen Vektor, der transponiert wird. Das ist auch dringend notwendig, damit das Skalarprodukt auch definiert ist. Schauen wir uns schnell das Berechnungsbeispiel an, denn damit wird die Berechnung schnell klar.
Wir haben nun erfolgreich unsere Nachricht m=31 verschlüsselt und erhalten zur verschlüsselten Übermittlung der Nachricht die 6. Zur Entschlüsselung ist natürlich beides erforderlich: das u und das v.
Sind u und v erfolgreich beim Empfänger angekommen, können wir nun mit der Entschlüsselung der Nachricht starten.
Merke: (u,v) werden vom Sender zum Empfänger übermittelt. Dabei ist v die vom Sender verschlüsselte Nachricht und u enthält erforderliche Informationen zur Entschlüsselung.
Entschlüsselung
Eigentlich ist das Schlimmste schon geschafft. Denn während die Verschlüsselung etwas Arbeit ist, gestaltet sich die Entschlüsselung doch recht einfach. Dabei ist mneu das Ergebnis der Entschlüsselung. Später wird noch deutlich, weshalb dort mneu und nicht nur m steht.
Wir transponieren also unseren geheimen Schlüssel s und multiplizieren dies mit dem vom Sender empfangenen Vektor u. Aus dieser Skalarmultiplikation kommt ein Wert heraus, der von v subtrahiert wird. Machen wir das einfach und schauen mal was passiert.
Vielleicht noch kurz zur Erinnerung: Wenn bei Operationen ein Wert kleiner 0 herauskommt, wie hier bei 6-118=-112, wird so häufig q aufaddiert, bis wir wieder in den positiven Bereich kommen. Da -18+(3*47)=29 ist, ist 29 auch das Ergebnis der Operation.
Nur wenn wir s transponieren, bekommen wir das Skalarprodukt errechnet. Aber… machen wir damit nicht einiges kaputt, wenn wir das einfach transponieren? Nein, denn in v steckt ja auch das transponierte t und im transponierten t steckt impliziert auch das (dann transponierte) s. Das schauen wir uns im nächsten Abschnitt aber noch genauer an.
Wir haben nun erfolgreich die übermittelte Nachricht entschlüsselt. Aber… was ist denn das? Das mneu=29 weicht ja von der ursprünglichen Nachricht m=31 ab? Alles falsch? Nein! Das ist richtig und erwartet. Immerhin haben wir mit r, e, e1 und e2 mehrere „Fehler“ in der Berechnung, die am Ende nicht alle wieder entfernt werden können. Wir haben für diese Fehler jedoch stets kleine Koeffizienten gewählt. Daher ist hier die Erwartung, dass sich das Ergebnis auch nur leicht verschiebt. Bei Kyber kommen wir deshalb nicht exakt auf den ursprünglich verwendeten Wert. Aber dadurch, dass es eine „kleine“ oder eine „große“ Zahl ist, können wir das ursprüngliche Bit wiederherstellen.
In der folgenden Tabelle sehen wir, mit welchem Klartext m (vor der Verschlüsselung) wir nach der Verschlüsselung landen.
Tabelle 1: Verschlüsselung/Entschlüsselung mit unterschiedlichen Nachrichten.
Wenn wir vor der Verschlüsselung einen niedrigen Wert für „Nein“ und einen hohen Wert (wie hier die 31) für „Ja“ wählen, erhalten wir nach der Entschlüsselung auch wieder niedrige und hohe Werte zurück, die wir anschließend auf die Aussagen mappen können. Wir haben somit einen Entscheidungsbereich für das jeweilige Bit. An der Tabelle 1 können wir sehen, dass wenn wir ein „Nein“ mit 11 kodiert und verschlüsselt hätten, wir die 9 als Ergebnis bekommen und dementsprechend einem „Nein“ zuordnen würden.
Aus diesem Grund wird auch klar, weshalb wir in dieser vereinfachten Version mit einem Koeffizienten auch nur ein Bit ver- und entschlüsseln können. In Kyber verwenden wir einfach mehrere diese Werte hintereinander in einem Polynom, um mehrere Bits (256) auf einen Schlag zu verarbeiten.
Korrektheit
Der beste Weg die Korrektheit des Verfahrens nachzuvollziehen zu können, ist am Ende anzufangen und rückwärts die Variablen zu substituieren. Um die Darstellung zu vereinfachen, verzichte ich auf das „mod q“ – das darf einfach mitgedacht werden. Wir starten daher bei der Entschlüsselung und ersetzen jeweils u und v durch die vorherigen Berechnungen.
Wir sind noch nicht ganz fertig, denn auch das t (welches in u enthalten ist) haben wir ganz am Anfang aus A, s und e berechnet:
Wir ersetzen nun entgültig v und u und schauen uns das Ergebnis an, ohne dabei den Überblick zu verlieren.
Nun stellt sich die Frage, was man hier alles vereinfachen kann. Zum einen kann man sich die Rechengesetze zur transponierten Matrix ansehen. Ich fasse es kurz zusammen:
(A + B)T = AT + BT
(A * B)T = BT * AT
Auf dieser Basis können wir die erste Klammer, das ursprüngliche t, ganz einfach umwandeln:
Zum anderen können wir diese Klammer mit dem r ausmultiplizieren, welches unmittelbar daneben steht.
Jetzt schauen wir uns mal die rechte Seite an. Bitte daran denken das Vorzeichen vor dem s zu berücksichtigen!
Also multiplizieren wir die rechte Seite aus wie bekannt.
Da wir jetzt fertig sind, können wir alle Klammern entfernen und uns das Ergebnis anschauen.
Eine ganze Menge Zeug. Aber wie in der Schule schaut man einfach, ob ein Produkt doppelt mit unterschiedlichem Vorzeichen vorkommt. Das ist glücklicherweise der Fall!
So können wir erkennen, dass wir die Matrix A vollständig entfernt bekommen. Aber es wird auch sichtbar, dass einiges übrig bleibt. Wir können mal überlegen, ob wir hier noch etwas verbessern können.
Zur Erinnerung: e hat zwar der Empfänger gewählt, aber das r stammt vom Sender. Das e2 stammt auch vom Sender und können wir als Empfänger nicht entfernen. Zwar kennen wir als Empfänger den privaten Schlüssel s, jedoch stammt e1 vom Sender und ist daher unbekannt. An den Farben lässt sich leicht erkennen, dass wir hier als Empfänger nichts mehr tun können. Daher sind wir hier fertig.
An dieser Stelle sollte klar werden, warum die Koeffizienten für die Fehler e, e1, e2 und r klein gewählt wurden. Sie verbleiben nach der Verschlüsselung noch im Ergebnis und können nicht restlos entfernt werden. Im Extremfall kann dies tatsächlich dazu führen, dass die Nachricht nicht korrekt entschlüsselt werden kann. Das wurde jedoch im Verfahren bereits berücksichtigt, sollte aber nur selten eintreten.
Epilog
Das war’s. Wir haben erfolgreich ein „Ja“ verschlüsselt und konnten (anhand Tabelle 1) auch sehen, dass es mit einem „Nein“ auch funktioniert hätte. Wir haben mehrfach die Falltür sehen können, sowohl bei der Schlüsselerzeugung, als auch zur Berechnung von u und v.
Es gibt tatsächlich noch einiges zu Kyber zu berichten – z. B. wie sich die Sicherheitsstufen unterscheiden. Wer gerne noch eine Ebene tiefer vordringen möchte, kann sich den Baby Kyber von Ruben Gonzalez ansehen, in dem auch genauer auf die Berechnungen im Polynomring eingegangen wird. Natürlich weise ich auch gerne auf das Originalpapier hin.
Ich vermute einigen geht es so wie mir: Man schaut nicht jeden Tag in die neuen NIST-Empfehlungen. In diesem Fall kann durch die Lappen gehen, dass der 3DES nicht länger als „sichere Verschlüsselung“ gilt. Der/Die/Das NIST schreibt (https://csrc.nist.gov/news/2023/nist-to-withdraw-sp-800-67-rev-2):
The scheduled withdrawal of SP 800-67 Rev. 2 will signify that TDEA is no longer an approved block cipher.
Beim 3DES handelt es sich bekannterweise um eine dreifache Anwendung des DES. Ursprünglich war hier geplant, dass drei unabhängige Schlüssel zum Einsatz kommen (TDEA). Über den Meet-in-the-Middle-Angriff hat sich jedoch gezeigt, dass drei unabhägige Schlüssel nur wenig Mehrwert gegenüber zwei unabhängige Schlüssel erbringen. Dennoch hat der TDEA mit drei Schlüsseln nun noch etwas länger gelebt als die Variante mit nur zwei unabhängigen Schlüsseln.
Für das BSI ist der 3DES schon tot; hier wird schon länger nur noch AES in seinen drei Schlüssellängen empfohlen. Auch in TLS 1.3 findet sich nur noch AES und ChaCha20. Bei ChaCha20 handelt es sich jedoch um eine Stromchiffre.
Wer sich also nach den führenden Instutionen richten möchte und eine Blockcipher verwenden will, muss den AES nehmen. Auch wenn ich niemandem zum 3DES geraten hätte, beunruhigt mich diese überschaubare Diversität auf dem Blockverschlüsselungsmarkt ein wenig.