In Foren oder auf Reddit gibt es immer wieder Diskussionen über die drohende Apokalypse im Netz, sollten Quantencomputer die etablierten asymmetrischen Verfahren brechen. Jedoch gibt es gute Gründe, optimistischer zu sein als noch vor drei Jahren. Cloudflare, als einer der größten Content-Delivery-Network-Anbieter, veröffentlicht regelmäßig Statistiken über das eigene Nutzerverhalten. Beispiele sind der Anteil von IPv4 (ca. 60 %) zu IPv6 (ca. 40 %) oder der am häufigsten verwendete User-Agent (Chrome).
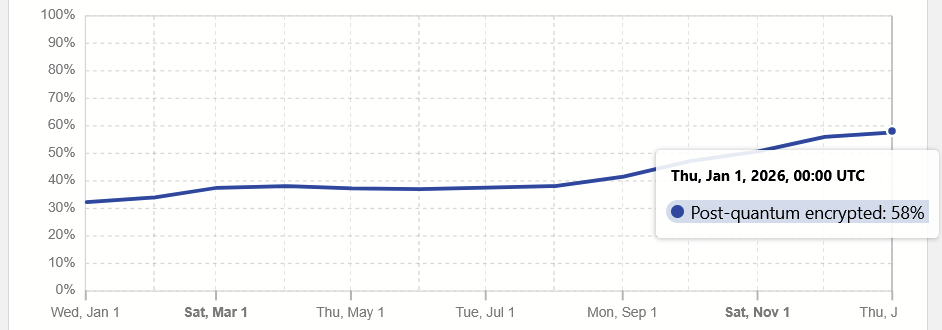
Enthalten ist auch eine Statistik zur Nutzung quantencomputersicherer Schlüsselaustauschverfahren. Konkret ist in diesem Fall X25519MLKEM768 gemeint. Es handelt sich um eine Kombination aus einem auf elliptischen Kurven basierenden Schlüsselaustausch und Kyber (ML-KEM). Browserseitig wird dies u. a. von Mozilla Firefox und Google Chrome unterstützt.
Während der Anteil im Januar 2024 bei 2,3 % lag, stieg er bis Januar 2025 auf ca. 30 %. Für Januar 2026 veröffentlicht Cloudflare einen Anteil von 58 %. Das bedeutet, dass bereits über die Hälfte des Traffics mit Verfahren abgesichert wird, die nach aktueller Einschätzung resistent gegenüber Quantencomputern sind.
Es ist zwar noch ein weiter Weg, insbesondere da in der Praxis ML-DSA-Zertifikate bislang kaum in Erscheinung treten. Dennoch ist es ein guter Anfang und eine insgesamt erfreuliche Entwicklung.
Kürzlich bin ich im Internet über die Frage gestolpert, ob der Einsatz von PIM in VeraCrypt immer sinnvoll ist. Zum Beispiel auch dann, wenn man den Container mit einem 128-stelligen zufälligen Passwort abschließt. Dabei handelt es sich um die maximal unterstützte Passwortlänge der Applikation.
Kurz zur Erinnerung: Bei PIM (Personal Iterations Multiplier) wird das eingegebene Passwort über ein hardwareintensives Verfahren zu einem Schlüssel abgeleitet. Ein einfaches Beispiel hierfür ist eine vielfache Hashbildung: Anstelle eine Passphrase direkt zu verwenden, durchläuft diese vorher mehrmals eine Hashfunktion. Dieser Vorgang kann durch einen Angreifer nicht abgekürzt werden. Somit wäre dieser gezwungen, jeden möglichen Passwortkandidaten in gleicher Weise zu behandeln. Dies stellt einen hohen Aufwand dar und verhindert so einen Offline-Brute-Force-Angriff. Auf diese Weise sind sogar Passwörter aus einem Wörterbuch schwierig zu brechen.
Es ist wichtig zu verstehen, dass bei VeraCrypt das vom Benutzer eingegebene Passwort, mit oder ohne PIM, nicht unmittelbar verwendet wird, um die Inhaltsdaten auf der Festplatte zu verschlüsseln. Vielmehr wird vor der Formatierung ein durch Mausbewegungen erzeugter zufälliger Schlüssel verwendet. Dieser Schlüssel wird anschließend auf dem Datenträger abgelegt. Damit nicht jeder die Daten damit entschlüsseln kann, wird der Schlüssel durch die Passphrase des Benutzers verschlüsselt. An dieser Stelle kommt dann PIM zum Einsatz. Soll der Datenträger aufgeschlossen werden, wird die Passphrase des Benutzers verwendet, durchläuft aufgrund von PIM mehrere Iterationen und wird am Ende zu einem Schlüssel abgeleitet, welcher den Schlüssel für die Inhaltsdaten entschlüsselt.
Warum findet eine solche Entkoppelung zwischen Benutzerpassphrase und dem tatsächlichen Schlüssel statt? Ganz einfach: Auf diese Weise ist sichergestellt, dass der Schlüssel für die Inhaltsdaten wirklich zufällig ist und es ist möglich, das Benutzerpasswort zu ändern, ohne alle Daten mit der alten Passphrase entschlüsseln und mit der neuen Passphrase verschlüsseln zu müssen.
Die Inhaltsdaten sind also mit einem 256-Bit-Schlüssel gesichert, welcher durch die Mausbewegungen des Benutzers erzeugt wurde. Besser wird der Schutz also nicht. Somit sind nur Passphrasen sinnvoll, die diese 256 Bit abdecken. Jedes zusätzliche Zeichen führt nur zu einer Dopplung, sodass zwei unterschiedliche Passwörter denselben Schlüssel erzeugen. Unter der Prämisse, dass wir Groß- und Kleinbuchstaben und die Ziffern 0 bis 9 verwenden, hilft der Logarithmus zur Bestimmung der maximal sinnvollen Länge:
Mehr als 43 Stellen sind für ein Passwort also nicht sinnvoll, sofern die Zeichen zufällig gewählt wurden. Mit 43 zufälligen Zeichen aus diesem Alphabet bekommen wir einen perfekten 256-Bit-Schlüssel.
Auf diese Weise lässt sich die ursprüngliche Frage beantworten. Wenn ein Angriff ohnehin auf die vollständige Schlüsselsuche aller 256-Bit-Schlüssel hinauslaufen müsste, könnte der durch PIM gesicherte Teil übersprungen werden. Mit einem zufällig gewählten Schlüssel, welcher die volle Schlüssellänge der Blockchiffre abdeckt, bringt der Einsatz von PIM somit keinen zusätzlichen Nutzen.
Kürzlich kam in einer Kommentarspalte zu einem Video die Frage auf, ob die Anforderung zur Bereitstellung von SSL/TLS gesetzlich normiert ist. Viele denken, dass die Bereitstellung eher optional ist, sofern keine personenbezogenen Daten übertragen werden. Aber dennoch bleibt die Frage, wie es abseits des Datenschutzes mit einer solchen Anforderung aussieht. Immerhin existieren noch Webseiten, die kein HTTPS anbieten, auch wenn es immer weniger werden.
Tatsächlich gab es aber schon im alten Telemediengesetz eine Regelung dazu und zwar im § 13 Abs. 7 TMG:
Diensteanbieter haben, soweit dies technisch möglich und wirtschaftlich zumutbar ist, im Rahmen ihrer jeweiligen Verantwortlichkeit für geschäftsmäßig angebotene Telemedien durch technische und organisatorische Vorkehrungen sicherzustellen, dass
kein unerlaubter Zugriff auf die für ihre Telemedienangebote genutzten technischen Einrichtungen möglich ist und
diese a) gegen Verletzungen des Schutzes personenbezogener Daten und b) gegen Störungen, auch soweit sie durch äußere Angriffe bedingt sind, gesichert sind.
Vorkehrungen nach Satz 1 müssen den Stand der Technik berücksichtigen. Eine Maßnahme nach Satz 1 ist insbesondere die Anwendung eines als sicher anerkannten Verschlüsselungsverfahrens.
Wer sich die Frage stellt, wer hier als „Diensteanbieter“ gilt, dann lässt sie sich dahingehend beantworten, dass es die selben natürlichen oder juristischen Personen sind, die ein Impressum anbieten müssen. Ich lehne mich so weit aus dem Fenster, dass dies für die deutliche Mehrheit der deutschsprachigen Webseiten der Fall ist.
Nun ist das TMG nicht mehr in Kraft und es könnte sich die Frage stellen, inwieweit eine solche Regelung in die neuen Normen übernommen wurde (oder nicht). Im Digitale Dienste Gesetz war dahingehend nichts auffindbar. Fündig wird man allerdings im § 19 Abs. 4 TDDDG (Telekommunikation-Digitale-Dienste-Datenschutz-Gesetz):
Anbieter von digitalen Diensten haben, soweit dies technisch möglich und wirtschaftlich zumutbar ist, im Rahmen ihrer jeweiligen Verantwortlichkeit für geschäftsmäßig angebotene digitale Dienste durch technische und organisatorische Vorkehrungen sicherzustellen, dass
kein unerlaubter Zugriff auf die technischen Einrichtungen, die sie für das Angebot ihrer digitalen Dienste nutzen, möglich ist und
die technischen Einrichtungen nach Nummer 1 gesichert sind gegen Störungen, auch gegen solche, die durch äußere Angriffe bedingt sind.
Vorkehrungen nach Satz 1 müssen den Stand der Technik berücksichtigen. Eine Vorkehrung nach Satz 1 ist insbesondere die Anwendung eines als sicher anerkannten Verschlüsselungsverfahrens. Anordnungen des Bundesamtes für Sicherheit in der Informationstechnik nach § 7d Satz 1 BSI-Gesetz bleiben unberührt.
Alte und neue Anforderung wirken also recht ähnlich. Meiner Einschätzung nach lässt sich somit, vorher wie nachher, die Pflicht auf TLS aus dem TDDDG ableiten. Allerdings würde es einem voraussichtlich ohnehin nicht gelingen, aus den Anforderungen des Art. 32 DSGVO herauszukommen.
Mal etwas aus der Welt der Hardware. Bei der Entwicklung einer kleinen IoT-Anwendung stand ich vor der Herausforderung festzustellen, ob der ESP32 genügend Leistung bieten würde. Es war jedoch keine einfache Aufgabe, eine leistungsstärkere WLAN-fähige Alternative zu finden. Obwohl ich Teensy-Boards für andere Anwendungszwecke äußerst interessant und leistungsstark finde, musste ich feststellen, dass sie keine Unterstützung für Wi-Fi bieten.
Allerdings gibt es da noch ein Bauteil, dass in den letzten Monaten etwas schwierig zu erhalten war, aber mittlerweile (Stand Oktober 23) wieder günstig zu erwerben ist: der Raspberry Pi Zero 2W. Dieser verfügt über 1 Ghz und Vier-Kern-Prozessor.
ESP32 (links) und Raspberry Pi Zero 2W (rechts)
Neben der Plattform stellt sich jedoch auch die Frage nach der Programmiersprache. Grundsätzlich lässt sich natürlich alles in C implementieren, aber bei komplexeren Anwendungen ist dies nicht unbedingt komfortabel. Und wenn man in der Implementierung was vergessen hat, zeigt sich sowas gerne erst einige Wochen bis Monate später.
Ein komfortablerer Ansatz wäre die Verwendung von Python im Sinne von MicroPython oder CircuitPython. Dies wirft jedoch die Frage auf, ob diese Lösungen zu viele Ressourcen beanspruchen. Aus diesem Grund führte ich einfaches Benchmarking durch. Dabei handelte es sich lediglich um das Inkrementieren einer Variablen, was natürlich nicht unbedingt repräsentativ ist. Dennoch reichte es aus, um ein Gespür für die Leistungsfähigkeit und den Ressourcenverbrauch der Plattformen zu erhalten.
Demzufolge verglich ich die Leistung von C auf dem ESP mit CircuitPython auf dem ESP und dem Raspberry Pi Zero. Darüber hinaus untersuchte ich, wie sich MicroPython auf einem Raspberry Pi Zero mit Betriebssystem verhält. Einige Tests führte ich auch mit mehreren Threads durch.
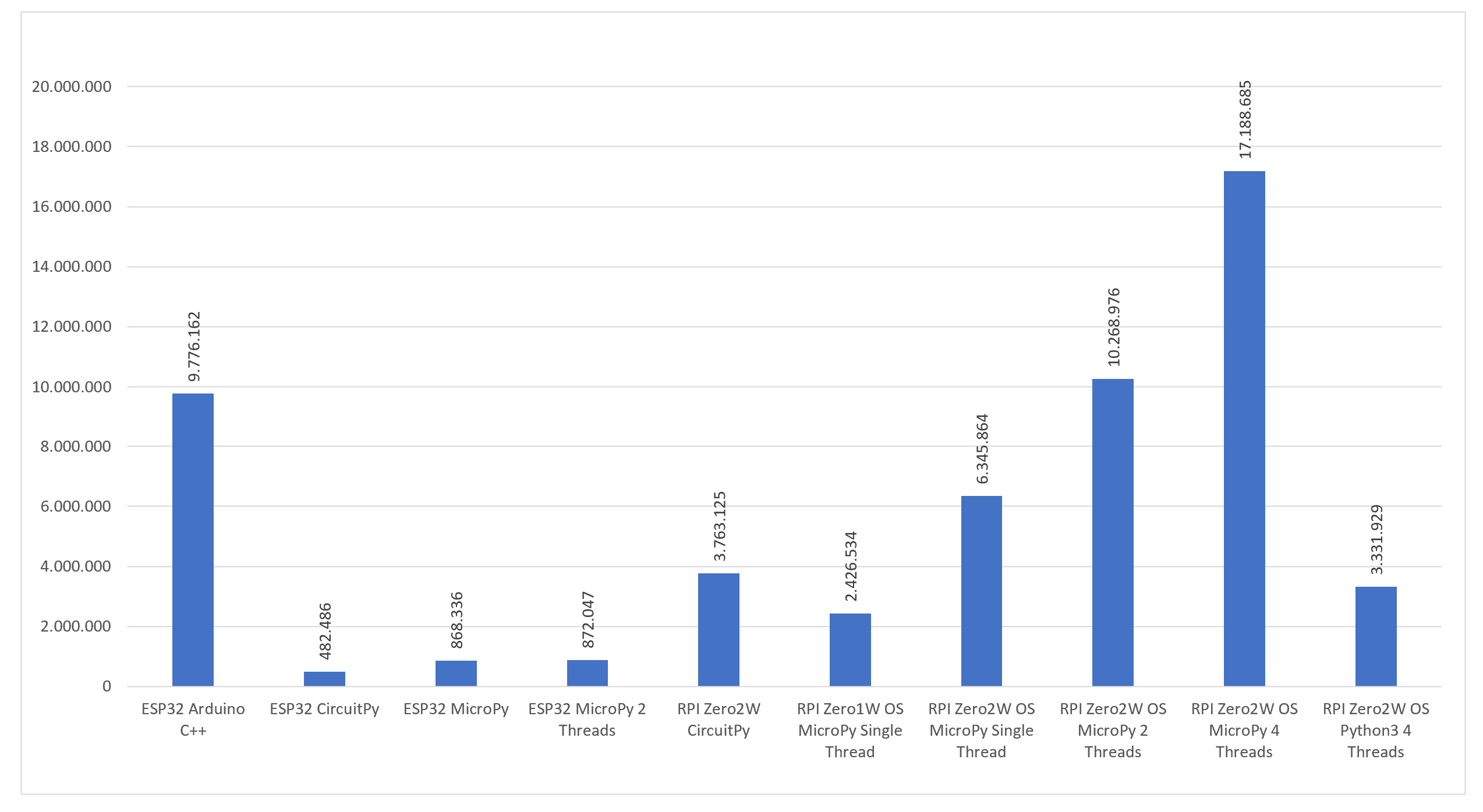
Benchmarkergebnisse Teil 1
Die aus diesen Ergebnissen abgeleitete Schlussfolgerung deutet darauf hin, dass CircuitPython im Vergleich zu anderen Optionen vergleichsweise langsam sein könnte. Es ist jedoch wichtig zu betonen, dass diese Schlussfolgerung ausschließlich auf den Ergebnissen dieses Tests basiert. Andere potenzielle Vorteile werden dabei nicht berücksichtigt.
Für mich persönlich war es überraschend, dass MicroPython auf einem Raspberry Pi Zero mit einer Raspbian Lite Installation äußerst gute Ergebnisse liefert. Ich hätte erwartet, dass das Betriebssystem zu viele Ressourcen verbraucht und somit den „Bare Metal“-Installationen unterlegen ist. Dies scheint jedoch nicht der Fall zu sein.
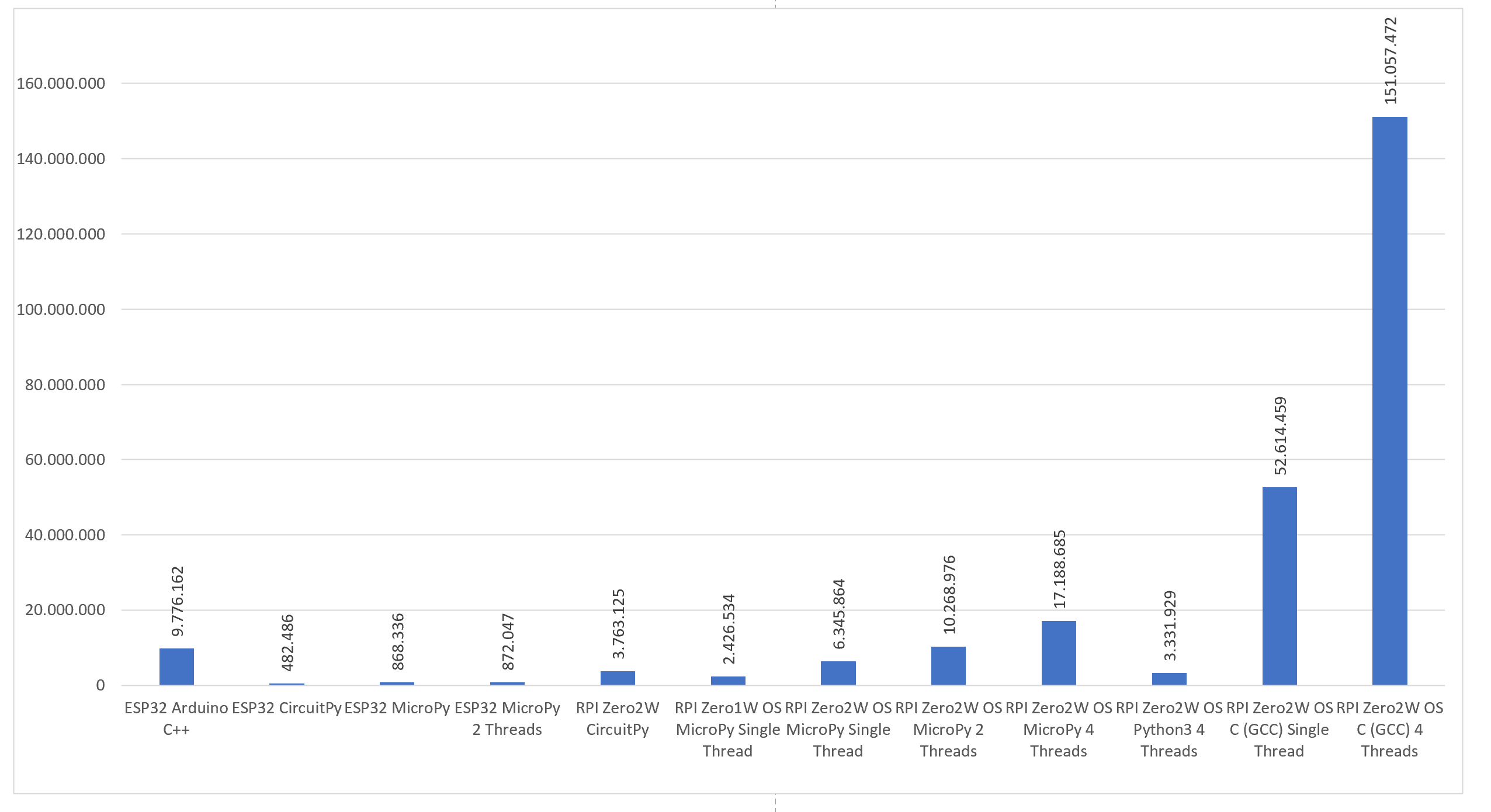
Auf Nachfrage eines Freundes hin habe ich noch eine C-Implementierung auf dem Pi mit (Raspbian Lite) OS getestet. Dies hätte ich besser nicht ausprobiert; der Vergleich von oben ergänzt um die Ausführung der C-Implementierung mit einem und vier Threads:
Benchmarkergebnisse Teil 2
Der Vollständigkeit halber sollte jedoch angemerkt werden, dass die vier Threads ohne Synchronisation (ohne Verwendung von Locks oder Mutex) ausgeführt wurden. Bei einer einfachen Inkrementierung schien dies nicht erforderlich zu sein.
Fazit: C(++) ist (leider) immer besser. Ursprünglich dachte ich die Differenz wäre viel geringer — die Ergebnisse vermitteln jedoch ein anderes Bild. Daher drängt sich die Frage auf, ob der Komfort einer Python-Implementierung bei so viel Leistungsverlust noch gerechtfertigt ist. Wenn man jedoch auf Python setzen möchte wäre die Wahl von MicroPython auf einem RaspberryPi Zero mit Betriebssystem die Beste.
Wir kennen es doch alle: Hin und wieder wird aus irgendeinem lästigen Grund ein neues Passwort oder eine neue PIN benötigt. Dabei soll es auch noch etwas sein, das sich leicht merken lässt und von den bisher verwendeten unterscheidet.
Insbesondere bei Multi-Faktor-Authentifizierung genügt auch schonmal eine vier-, sechs- oder achtstellige PIN: Wenn wir eine neue EC-Karte, einen neuen Personalausweis erhalten oder zur Entsperrung unseres Smartphones. Aber wie sieht es eigentlich mit der Sicherheit von solchen PINs aus?
Grundsätzlich lehrt uns die Kombinatorik, dass bei 10 unterschiedlichen Ziffern (0-9) zur Auswahl und bei einer vierstelligen PIN genau 10 hoch 4 also 10.000 verschiedene Kombinationen existieren. Im schlechtesten Fall müssten diese alle ausprobiert werden — im Mittel würde ein Angreifer nach der Hälfte, also nach 5000 Versuchen, die korrekte PIN durch systematisches Ausprobieren ermitteln können.
Üblicherweise sperren sich aber Geräte nach mehrmaligen Fehleingabe: Dies ist häufig schon bei drei Fehlversuchen der Fall. So betrachtet sind die vierstelligen PINs also nicht so übel: Die Wahrscheinlichkeit bei drei Versuchen die korrekte PIN in einem dieser Versuche zu wählen liegt bei 0,03 %.
Aber dabei darf auch die Realität nicht vergessen werden: Auf den Tasten des Gerätes hinterlassen wir stets einen Fingerabdruck der häufig auch ohne Hilfsmittel erkennbar ist. Insbesondere bei der Glasscheibe eines Smartphones ist dies vermutlich jedem schon selbst aufgefallen. Probleme dieser Art wurden auch schon im Beitrag Neulich im Supermarkt angedeutet. Wenn wir nun vor der Auswahl einer PIN stehen, möchten wir es dem potenziellen Angreifer möglichst schwer machen. Intuitiv würde man also vermutlich eine PIN wählen die aus vier verschiedenen Ziffern besteht um eine möglichst hohe Sicherheit zu erzielen. Aber ist das wirklich besser?
In der Schule lernt man (häufig), dass sich die Anzahl der möglichen Permutationen (Anordnungen) von n-vielen Elementen über die Fakultätsfunktion n! berechnen lässt. So lassen sich vier verschiedene Ziffern auf 4!=24 unterschiedliche Arten anordnen. Aber es könnte auch sein, dass nur zwei verschiedene Ziffern verwendet wurden oder nur drei oder sogar nur eine Ziffer. Wie berechnet man in so einem Fall die Anzahl der Möglichkeiten?
Hierzu betrachten die Anzahl der Permutationen mit nicht unterscheidbaren Elementen. Sind m von insgesamt n Objekten nicht unterscheidbar, können diese auf m! verschiedene Positionen verteilt werden. Die Anzahl der Permutationen insgesamt (n!) werden um diese Kombinationen reduziert.
\frac{n!}{m_1! \cdot m_2! \cdot \ldots}
Die m1, m2, etc. stellen dabei die Gruppen von mehrfach vorkommenden Elementen dar. Als Beispiel: Hinterlassen wir nach Eingabe der PIN nur einen Fingerabdruck auf der Taste 4 so gibt es vier nicht unterscheidbare Elemente (m1=4) und somit ergibt sich:
\frac{4!}{4!}=1
Wenn wir hingegen auf zwei Tasten, z. B. der 3 und der 5 einen Fingerabdruck hinterlassen wissen wir nicht, ob die Zahl 3 einmal, zweimal oder dreimal in der PIN genutzt wird. In Frage kommen daher Kombinationen wie (3,3,3,4) aber auch (4,4,3,3) oder (4,4,4,3). Somit missen wir zweimal eine Gruppe von 3 identischen Ziffern berücksichtigen (die Ziffer 3 dreifach oder die Ziffer 4 dreifach) und zusätzlich die Permutationen, wenn die Ziffer 3 und die Ziffer 4 beide doppelt verwendet wurden. In diesem Fall erhalten wir 14 Möglichkeiten diese anzuordnen.
\frac{4!}{3!}+\frac{4!}{2!*2!}+\frac{4!}{3!}=14
Wie sieht das Ganze bei drei verschiedenen Ziffern aus? Sehen wir beispielsweise bei der 1, der 2 und der 3 einen Fingerabdruck, muss eine Ziffer doppelt genutzt worden sein. Wir berechnen die möglichen Permutationen bei (1,1,2,3). Wir wissen aber nicht welche der drei Ziffern doppelt verwendet wurde. So könnten auch Permutationen von (2,2,1,3) oder (3,3,1,2) in Frage kommen. Daher müssen wir diese drei Mal addieren.
Bei vier unterschiedlichen Ziffern hingegen, erhalten wir ganz klassisch (Permutationen ohne Wiederholung) die bereits oben beschriebenen 24 verschiedene Kombinationen. Wir können uns diese zwei Fälle auch in Python generieren und anzeigen lassen. Hierzu kann die Methode permutations aus itertools hilfreich sein.
from itertools import permutations
kombinations = [[1,1,2,3],[2,2,1,3],[3,3,1,2]]
#kombinations = [[1,2,3,4]]
all = []
for k in kombinations:
perm = permutations(k)
for i in list(perm):
if i not in all:
all.append(i)
print(all)
Betrachten wir die Ergebnisse in der Tabelle sehen wir, dass die meisten Permutationen bei 3 Ziffern zustande kommen. Dies natürlich unter der Prämisse, dass wir nicht wissen welche der drei Ziffern doppelt verwendet wurden.
1 Ziffer
2 Ziffern
3 Ziffern
4 Ziffern
1 Permutationen
14 Permutationen
36 Permutationen
24 Permutationen
Zusammenfassend ist zu sagen, dass sofern nur diese Art des Angriffs, dass ein Angreifer auf Basis der Fingerabdrücke oder anderen Spuren die Ziffern der PIN ermitteln kann berücksichtigt wird, eine PIN aus drei verschiedenen Ziffern am sichersten ist. Unnötig zu sagen, dass sich dieses Muster auch bei fünf- oder sechsstelligen PINs fortsetzt: Es ist stets besser eine Ziffer doppelt zu verwenden. Insbesondere sollte von einer PIN mit zwei Ziffern abgesehen werden, da ein Angreifer bei drei Versuchen diese mit einer Wahrscheinlichkeit von 21 % erraten würde; bei 3 Ziffern sinkt die Wahrscheinlichkeit hingegen auf 8,3 %.
Ich bin kürzlich über eine Datenschutzerklärung gestolpert, die einen interessanten Absatz zum Thema Datensicherheit enthielt:
Wir verwenden innerhalb des Website-Besuchs das verbreitete SSL-Verfahren (Secure Socket Layer) in Verbindung mit der jeweils höchsten Verschlüsselungsstufe, die von Ihrem Browser unterstützt wird. In der Regel handelt es sich dabei um eine 256 Bit Verschlüsselung. Falls Ihr Browser keine 256-Bit Verschlüsselung unterstützt, greifen wir stattdessen auf 128-Bit v3 Technologie zurück.
Eine schnelle Googlesuche zeigte, dass dieser Textbaustein in vielen Datenschutzerklärungen zu finden ist. Interessanterweise auch in Webauftritten von Kanzleien und Datenschutzberatern. Meine Vermutung ist, dass diese Textpassage aus einem nicht ganz sauberen Datenschutzgenerator stammt, denn die von mir betrachteten Webseiten hatten mehrheitlich ihre Datenschutzerklärungen im Zuge der DS-GVO im Jahr 2018 angepasst.
Wollen wir uns jedoch den Inhalt mal etwas genauer ansehen. Mit den 256-Bit ist wohl die Schlüssellänge der symmetrischen Chiffre gemeint. Wie jedoch schon unlängst bekannt ist, stellt diese Angabe nur einen kleinen Teil der Sicherheit dar. Die gesamte SSL/TLS Ciphersuite entscheidet über die Sicherheit. Mit Verabschiedung von TLS 1.3 wurden beispielsweise alle CBC-Modi in den symmetrischen Chiffren entfernt – zuoft waren diese für Verwundbarkeiten mitverantwortlich. Dies gilt gleichermaßen für beide Schlüssellängen, weshalb die Angabe ob Chiffren mit 256 Bit oder 128 Bit zum Einsatz kommen kein Qualitätsmerkmal darstellt.
Etwas mehr musste ich über die v3-Technologie grübeln. In Verbindung mit der Schlüssellänge der symmetrischen Chiffre ergibt dies keinen Sinn. Mir ist keine Versionierung bekannt, die in gleicher Weise auf alle symmetrischen Chiffren zutreffen würde. Die Angabe bezieht sich also vermutlich auf die SSL-Version. Es soll, meiner Vermutung nach, dies zum Ausdruck bringen, dass sofern SSL 3.1 (=TLS 1.0) nicht vom Browser unterstützt wird, SSL 3.0 verwendet wird. Würde dies in der Anwendung tatsächlich zutreffen, wäre die Webseite hochgradig angreifbar, da SSL 3.0 schon seit 2015 als unsicher eingestuft und in modernen Browser nicht länger nutzbar ist. Auch SSL 3.1 und TLS 1.1 werden im Laufe des Jahres 2020 in den Ruhestand gehen.
Es entbehrt nicht einer gewissen Ironie, dass SSL 3.1 im Jahr 1999 veröffentlicht wurde und auch von älteren Betriebssystemen wie Windows XP und Windows Server 2003 Unterstützung fand. Der Satz stellte jedenfalls schon damals keinen Mehrwert dar, da eine symmetrische 256 Bit Verschlüsselung nicht zwangsweise über eine mit 128 Bit zu stellen ist. So würde ich damals wie heute ein AES128 über ein RC4 mit 256 Bit Schlüssellänge stellen. Es ist sogar schon in einer gewissen Weise bedenklich, wie lange sich dieser sinnbefreite Textbaustein im Netz gehalten hat.
bei der Betrachtung von Whitepapern zu Produkten wird man häufig mit diversen Bingo-Begriffen überflutet. Auf diese Weise soll dem uninformierten Interessenten, das ist zumindest meine Vermutung, ein Gefühl von Expertise vermittelt werden. Ein Beispiel ist das Whitepaper von schul.cloud der heinekingmedia GmbH in Hannover. In ihrer Stellungnahme zum Datenschutz und den detaillierten Informationen zur Verschlüsselung werden mit diversen Begriffen hantiert, deren nähere Betrachtung lohnenswert ist.
Bildzitat aus dem Whitepaper (Quelle: schul.cloud).
TLS Transport Verschlüsselung: 4096 Bit RSA Schlüssel
Grundsätzlich ist natürlich nichts einzuwenden, wenn mit einer größeren Schlüssellänge (4096 Bit) als üblich (2048 Bit) wirbt. Wenn man sich allerdings das Zertifikat des Webauftritts anschaut findet sich hier nur einen 2048 Bit Schlüssel. Natürlich ist es möglich, dass es sich bei diesem Dienst um einen anderen Endpunkt handelt, allerdings ist es fraglich, weshalb hier nicht konsequent alle Endpunkte den gleichen Schutz aufweisen. Dies würde mein Vertrauen zumindest erhöhen, auch wenn es nicht unbedingt erforderlich ist. Die sonst übliche Argumentation, dass dies ggf. Mobilgeräte überfordern könnte, kann an dieser Stelle jedenfalls nicht herhalten.
Signierungsalgorithmus: SHA256withRSA
Mir ist unklar, welche Information daraus entnommen werden soll. Natürlich sollte kein MD5 oder SHA1 Hashverfahren zur Signaturerzeugung angewendet werden, aber es ist kaum ein Qualitätsmerkmal das speziell beworben werden muss. Klingt aber kryptisch, technisch und aus diesem Grund möglicherweise überzeugend.
Downgrade Attack Prevention
Ich finde es etwas befremdlich, dass mit Absicherungen nach dem Stand der Technik Werbung betrieben wird. Das SSLv3 abgeschaltet sein muss sollte mittlerweile allen Verantwortlichen bekannt sein. Die meisten Client-Bibliotheken würden dies ohnehin nicht länger unterstützen. Auch der Wechsel von HTTPS auf HTTP kann leicht in dieser kontrollierten Client/Server-Umgebung ausgeschlossen werden. Aber Attack Prevention klingt, als ob extreme Schutzmaßnahmen getroffen wurden – was tatsächlich passiert ist: eine Zeile in der Konfigurationsdatei des Servers.
Secure Renegotiation
Wer mehr darüber erfahren möchte, muss sich einfach den CVE-Eintragaus dem Jahr 2009 durchlesen. Ich finde es einfach ärgerlich, schon fast etwas sträflich, mit Standards werben, die bald ihr 10 Jähriges Jubiläum feiern.
Wichtige Fragen bleiben hingegen offen: Woher stammt das Schlüsselmaterial? Welche Kontrolle hat der Nutzer über das Schlüsselmaterial? Wie wird der Gesprächspartner authentisiert?
Insbesondere der letzte Punkt wird in vielen Messengern vernachlässigt. Threema hat dies durch eine manuelle Prüfung und Ampel-Symbolik gelöst. Whatsapp verheimlicht den Wechsel öffentlicher Schlüssel bzw. blendet diesen nur auf Verlangen ein. Damit gibt es bei Whatspp keine wirksame Authentifizierung. Möglicherweise ist das je nach Anwendungskontext auch nicht notwendig, aber es sollte dem Nutzer zumindest klar sein.
derzeit scheinen Audits von automatischen Update-Funktionen (wieder) hoch im Kurs zu sein. So aktuell auf heise.de zu Keepass 2. Auch ASUS-Geräte ziehen ihre Updates über unverschlüsselte HTTP-Verbindungen. Vor wenigen Tagen fand man auch etwas bei Lenovo-Geräten auf golem.de – wobei Lenovo bzgl. unsicherer Bloatware häufiger in der Kritik steht. Die Frage ist, woher diese Probleme stammen.
Eine unverschlüsselte Verbindung ist auf den ersten Blick nicht zu entschuldigen, denn immerhin werden hier Daten übertragen, die bzgl. ihrer Integrität geschützt werden müssen. Viele Security Consultants werden in so einem Fall empfehlen, man soll (einfach!) mittels SSL/TLS die Verbindung schützen, das Zertifikat (Signatur, Common Name, etc.) innerhalb der Applikation auf Gültigkeit prüfen und nur über eine solch geschützte Verbindung das Update beziehen. Damit hat man sowohl Vertraulichkeit als auch Integrität erschlagen. Anschließend werden die Findings im Audit-Bericht von rot auf grün gesetzt und eine Rechnung geschrieben. Während der Umsetzung wird man jedoch schnell merken, dass es doch nicht so einfach ist.
Ist SSL/TLS erstmal aktiviert muss man sich nämlich der Frage stellen, welche Settings beim Web-Server eingestellt werden. Je restriktiver und damit „sicherer“ ich diese Konfiguration vornehme, desto eher nehme ich Inkompatibilitäten mit alten Browsern in Kauf. Sind die Settings „zu stark“, schließe ich Clients aus und sind sie „zu lasch“, ruft dies wieder Kritiker hervor. Ein Beispiel ist z.B. Perfect Forward Secrecy was bei Windows XP-Nutzern zu Problemen führen kann. Auf ssllabs.com (wer möchte, kann es mit dieser Domain testen) können diese Settings geprüft werden und man erhält im Anschluss ein Rating. Dabei werden auch Verbindungstests mit Clients durchgeführt und zeigt, welche Betriebssystem/Browser-Kombinationen mit den aktuellen Settings ausgeschlossen werden. Natürlich muss diese Abwängung stets durchgeführt werden, wenn man eine Webseite im Internet anbietet. Allerdings kann man hier ggf. auch einen HTTP-Fallback bereitstellen. Dies ist im Autoupdate-Fall nicht möglich.
Die Software kann natürlich mit allen notwendigen Software-Librarys ausgeliefert werden, damit ein „immer funktionieren“ garantiert ist. Aber ob es tatsächlich wünschenswert ist, dass jede Kleinstanwendung Bibliotheken für einen SSL-fähigen Webclient beinhaltet ist sehr fraglich. Denn so müsste die Anwendung auch für alle Sicherheitslücken in diesen Librarys aktualisiert werden. Das zieht einen riesigen Rattenschwanz hinter sich her.
Noch schwieriger ist die Überprüfung des Zertifikates. Entweder man verlässt sich hierbei auf die PKI oder man führt eine manuelle Überprüfung des Fingerprints durch. Die Nutzung der PKI hat den Vorteil, dass ich nur (einem oder mehreren) Wurzelzertifikat(en) vertraue und so jederzeit ein neues Zertifikat ausgestellt werden kann. Der Nachteil ist, dass andere dies ggf. ebenfalls können: ich also gezwungen bin, der organisatorischen Sicherheit einer PKI zu vertrauen. Ein manueller Fingerprintvergleich führt zu dem Problem, dass sobald das eigene Zertifikat kompromittiert oder verloren ist, die Anwendung manuell aktualisiert werden müsste.
Eins ist sicher: Viel kritischer als ein fehlendes Update-Verfahren ist ein implementiertes, dass nicht (mehr) funktioniert. Und auch wenn der Einsatz von HTTPS mittlerweile ein Standard ist, führt es leicht zu unvorhersehbaren Problemen, die man vorher nur aufwendig testen kann. Bei so einem wichtigen Mechanismus möchte man jedoch nur ungern Fehler riskieren.
Der Beitrag soll NICHT den Eindruck vermitteln, diese Probleme wären nicht lösbar. Es soll nur zeigen, dass es keine ganz einfache Lösung gibt bzw. solche Systeme denkintensiver sind, als sie auf den ersten Blick scheinen. Alternative Verfahren, z.B. Softwaresignaturen, bleiben an dieser Stelle mal out of scope.
Hinweis: Dieser Webauftritt bietet aktuell noch kein HTTPS an. Da weder Cookies verteilt, noch ein Login angeboten wird, gab es bis zum heutigen Tage auch noch keinen Grund für einen solchen Schutz der Vertraulichkeit. Trotzdem soll dies in naher Zukunft geändert werden.
was macht man an einem Feiertag mit schönem Wetter üblicherweise? Richtig, man sieht sich den vom BSI veröffentlichten Bericht zur Lage der IT-Sicherheit in Deutschland 2015 an! Man muss vorab schon mal sagen, dass der Bericht sehr schön ausgestaltet ist – sowohl optisch, als auch inhaltlich.
Mein persönliches Highlight war der Abschnitt über den Cyber-Angriff auf den Deutschen Bundestag. Nach der Aussage im Dokument wurde dabei nach der „klassischen APT-Methode“ vorgegangen. APT (Advanced Persistent Threat) ist ein Sammelbegriff für professionelle/gezielte Angriffe. Es gibt jedoch keine klare Abgrenzung zu „einfachen“ Angriffen, sondern wird eher über Beispiele definiert: Stuxnet war ein APT – eine Ransomware im Krankenhaus ist kein APT. Durch diese Verknüpfung mit besonders kritischen Beispielen zuckt jeder IT-Verantwortliche innerlich zusammen, wenn er von einem APT hört.
Das Vorgehen der Angreifer wird auf Seite 26 beschrieben und kann so zusammengefasst werden:
Einzelne Arbeitsplatzrechner wurden infiziert.
Tools wurden nachgeladen.
Backdoors wurden installiert, sowie weitere Schadprogramme und Keylogger.
E-Mail-Postfächer wurden sich angesehen.
Mit anderen Worten: Ein Angreifer erlangt unberechtigt Zugriff, installiert sich weitere Software auf dem System und schaut anschließend was es noch alles gibt.
Man kann natürlich nicht widerlegen, dass es ein gezielter Angriff sein könnte. Ich bezweifle nur ein wenig die Argumentation dafür im Dokument, Zitat:
„Bei der Ausbreitung im internen Netz („Lateral Movement“) setzen die Angreifer auf gängige Methoden und öffentlich verfügbare Tools, wie sie auch von weniger professionellen Tätern verwendet werden. Dies kann dadurch begründet sein, dass man eine Zuordnung des Angriffs erschweren wollte.“
Es war also deshalb ein APT, weil es nicht aussieht wie ein APT. Gut, die Informationen sind hier auch sehr knapp gehalten. Aber ich habe trotzdem die Spur eines Verdachts, dass hier auch politischen Gründe im Spiel waren: Da einfache Angriffe auf einer so kritischen Infrastruktur ja grundsätzlich ausgeschlossen sind, muss es ein professioneller gewesen sein.
Weiteres aus dem Bericht FYI:
Schwachstellen. Abbildung 2 (Seite 10) zeigt eine Auflistung von verbreiteten Softwareprodukten und deren Schwachstellen im Jahr 2015. Wenig überraschend ist Flash mal wieder auf Platz 1. Platz 9 wird euch sicher überraschen … Java. Aus der Hardware-Ecke wird ein Angriff vom Juli 2015 beschrieben, welche über ein USB-Stick eine Fernsteuerung des Rechners durch das Intel-Management-System (vPro) ermöglicht.
Kryptographie. Hier gab es im Jahr 2015 wohl wenig Neues (zumindest aus Sicht des BSI). Erwähnt werden die Angriffe FREAK (SSL/TLS) und Logjam.
Ransomware im Krankenhaus. Das kennen wir natürlich schon. Immerhin wird der Angriff, wie von mir auch, als „heute Alltag“ eingestuft. Das Wort „Cyber-Kriminelle“ hätte man sich jedoch auch sparen können.
Social Engineering per Telefon. Auch in meinem erweiterten Bekanntenkreis ist jemand Opfer von einem „Microsoftmitarbeiter“ geworden, der den naiven Nutzer zur Installation von Fernwartungssoftware aufgefordert hat.
Statistiken zu Spam und Botnetzen.
Eine Drive-by-Exploit Übersicht (Abbildung 10, Seite 32) hat mir sehr gut gefallen. Es zeigt in einer Zeitleiste die kritischen Exploits und die ausgenutzte Schwachstelle (CVE).
Außerdem gibt es noch einen Ausflug ins neue IT-Sicherheitsgesetz, welches seit Mitte 2015 in Kraft ist.
Es gibt jedoch noch mehr, mal drüberblättern lohnt sich auf jeden Fall.
soziale Netzwerke sind ein endloser Quell der Freude:
[BLOG] 8 wichtige Gründe, warum du Java lernen solltest. → Nr. 6 wird dich überraschen
[…]
6) Durch die Programmierung in Bytecode ist Java weniger Virenanfällig
Java-Programme können vor der Ausführung verifiziert werden, da sie keine Zeiger haben und in Bytecode vorliegen. Die Verifizierung wird von Web-Browsern benutzt, um sicherzustellen, dass keine Viren enthalten sind. Java verwendet nicht Adressen aus Zahlen, sondern Namen für Funktionen und Methoden, die leicht überprüft werden können. So kann kein Java -Applet etwas ausführen oder auf etwas zugreifen, was nicht ausdrücklich im Verifizierungsprozess definiert worden ist.
Es stimmt, 6 hat mich überrascht. Wenn man sich anschaut, dass die Java SRE allein 2016 auf sechs 10er CVE-Ratings gekommen ist, ist das schon sehr bezeichnend. Für die, die es nicht kennen: die Skala beschreibt die Schwere der Verwundbarkeit mit einer Zahl zwischen 1.0 (unbedeutend) und 10.0 (katastrophal).
Es ist zwar schon richtig, dass seit Java 7u51 das Applet gültig signiert sein muss. Aber wenn die darunterliegende Sandbox kompromitiert ist, kann man sich das natürlich sparen. Nicht umsonst bleibt in Browsern wie Firefox das Java-Plugin deaktiviert bis es wirklich gebraucht wird. Außerdem war es noch nie ein Problem an „irgendein“ gültiges Zertifikate zu kommen – man ist ja hier nicht auf ein bestimmtes angewiesen. Sowas kennen wir auch schon aus dem Hause Microsoft.
Es gibt ganz sicher gute Gründe Java zu lernen, die Security würde ich dabei jedoch nicht anführen.