Mal etwas aus der Welt der Hardware. Bei der Entwicklung einer kleinen IoT-Anwendung stand ich vor der Herausforderung festzustellen, ob der ESP32 genügend Leistung bieten würde. Es war jedoch keine einfache Aufgabe, eine leistungsstärkere WLAN-fähige Alternative zu finden. Obwohl ich Teensy-Boards für andere Anwendungszwecke äußerst interessant und leistungsstark finde, musste ich feststellen, dass sie keine Unterstützung für Wi-Fi bieten.
Allerdings gibt es da noch ein Bauteil, dass in den letzten Monaten etwas schwierig zu erhalten war, aber mittlerweile (Stand Oktober 23) wieder günstig zu erwerben ist: der Raspberry Pi Zero 2W. Dieser verfügt über 1 Ghz und Vier-Kern-Prozessor.

Neben der Plattform stellt sich jedoch auch die Frage nach der Programmiersprache. Grundsätzlich lässt sich natürlich alles in C implementieren, aber bei komplexeren Anwendungen ist dies nicht unbedingt komfortabel. Und wenn man in der Implementierung was vergessen hat, zeigt sich sowas gerne erst einige Wochen bis Monate später.
Ein komfortablerer Ansatz wäre die Verwendung von Python im Sinne von MicroPython oder CircuitPython. Dies wirft jedoch die Frage auf, ob diese Lösungen zu viele Ressourcen beanspruchen. Aus diesem Grund führte ich einfaches Benchmarking durch. Dabei handelte es sich lediglich um das Inkrementieren einer Variablen, was natürlich nicht unbedingt repräsentativ ist. Dennoch reichte es aus, um ein Gespür für die Leistungsfähigkeit und den Ressourcenverbrauch der Plattformen zu erhalten.
Demzufolge verglich ich die Leistung von C auf dem ESP mit CircuitPython auf dem ESP und dem Raspberry Pi Zero. Darüber hinaus untersuchte ich, wie sich MicroPython auf einem Raspberry Pi Zero mit Betriebssystem verhält. Einige Tests führte ich auch mit mehreren Threads durch.
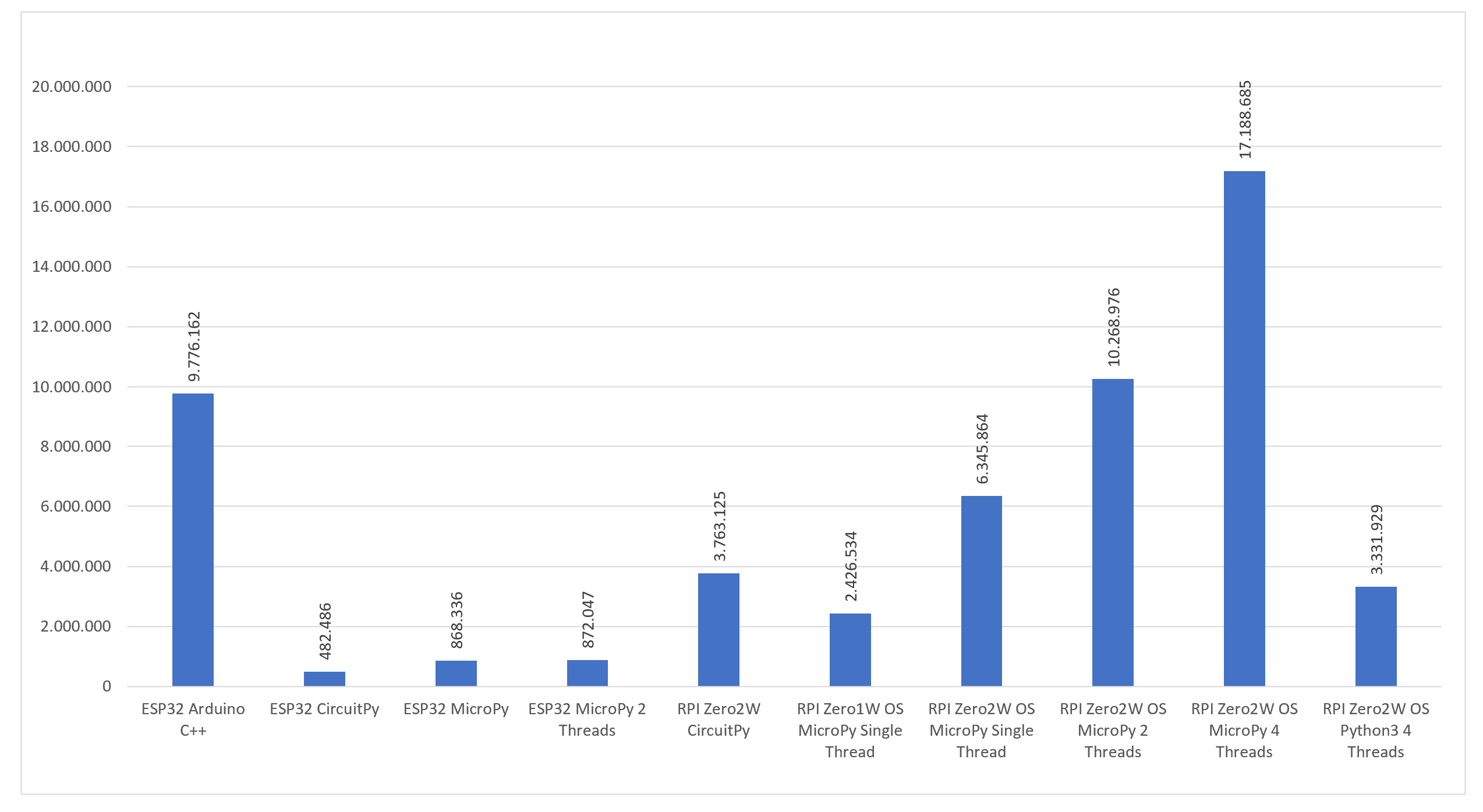
Die aus diesen Ergebnissen abgeleitete Schlussfolgerung deutet darauf hin, dass CircuitPython im Vergleich zu anderen Optionen vergleichsweise langsam sein könnte. Es ist jedoch wichtig zu betonen, dass diese Schlussfolgerung ausschließlich auf den Ergebnissen dieses Tests basiert. Andere potenzielle Vorteile werden dabei nicht berücksichtigt.
Für mich persönlich war es überraschend, dass MicroPython auf einem Raspberry Pi Zero mit einer Raspbian Lite Installation äußerst gute Ergebnisse liefert. Ich hätte erwartet, dass das Betriebssystem zu viele Ressourcen verbraucht und somit den „Bare Metal“-Installationen unterlegen ist. Dies scheint jedoch nicht der Fall zu sein.
Auf Nachfrage eines Freundes hin habe ich noch eine C-Implementierung auf dem Pi mit (Raspbian Lite) OS getestet. Dies hätte ich besser nicht ausprobiert; der Vergleich von oben ergänzt um die Ausführung der C-Implementierung mit einem und vier Threads:
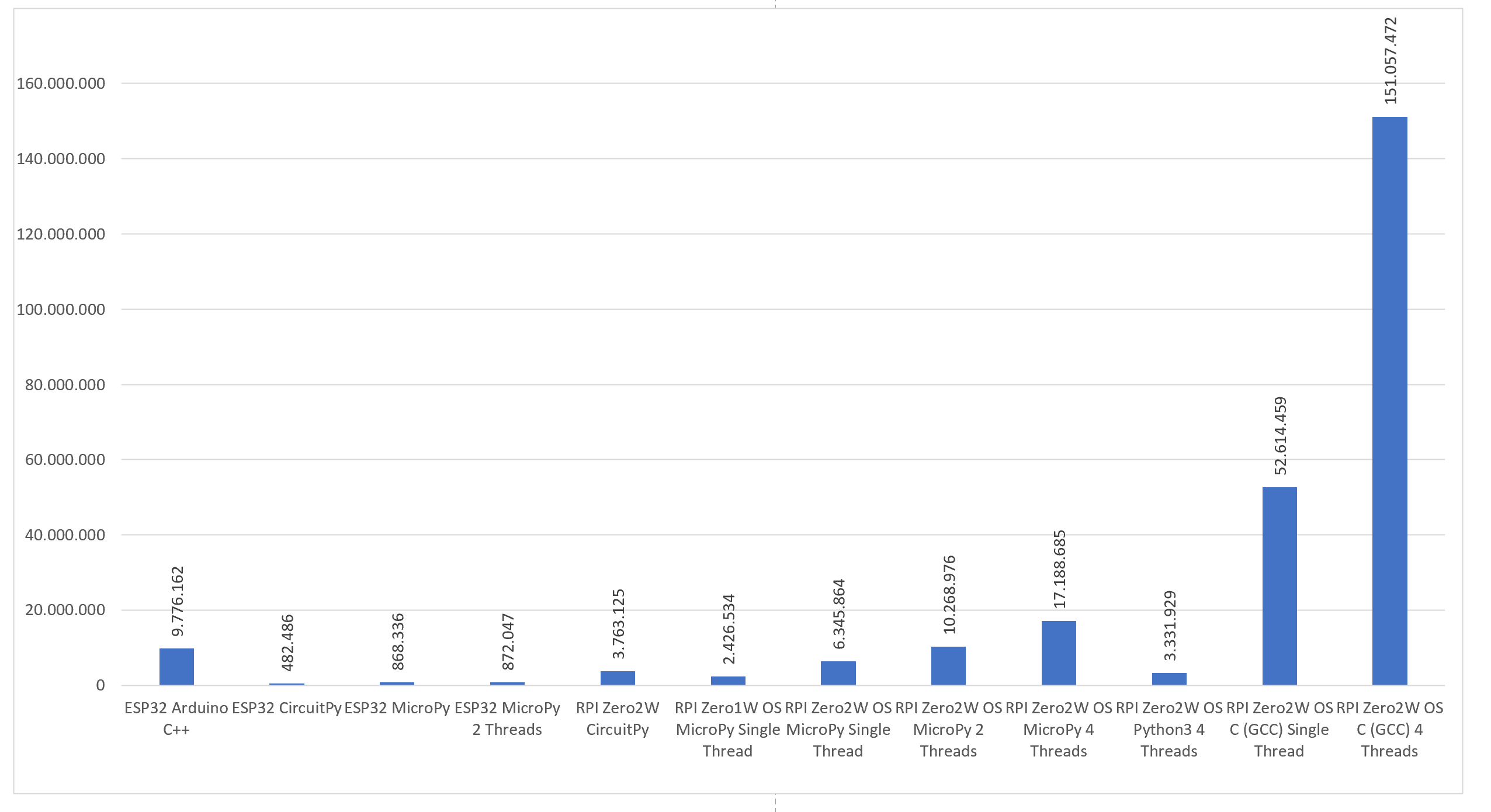
Der Vollständigkeit halber sollte jedoch angemerkt werden, dass die vier Threads ohne Synchronisation (ohne Verwendung von Locks oder Mutex) ausgeführt wurden. Bei einer einfachen Inkrementierung schien dies nicht erforderlich zu sein.
Fazit: C(++) ist (leider) immer besser. Ursprünglich dachte ich die Differenz wäre viel geringer — die Ergebnisse vermitteln jedoch ein anderes Bild. Daher drängt sich die Frage auf, ob der Komfort einer Python-Implementierung bei so viel Leistungsverlust noch gerechtfertigt ist. Wenn man jedoch auf Python setzen möchte wäre die Wahl von MicroPython auf einem RaspberryPi Zero mit Betriebssystem die Beste.